
The way we write code, deploy applications, and manage scale is constantly changing and evolving to meet the growing demands of our stakeholders. In the past, companies commonly deployed and maintained their own infrastructure. In recent times, everyone is moving to the cloud. The cloud is pretty nebulous (heh) though and means different things to different people. Maybe one day in the future, developers will be able to just write code and not worry about how or where it's deployed and managed.
That future is here and it's called serverless computing. Serverless computing allows developers to focus on writing code, not managing servers. Serverless functions further allow developers to break up their application into individual pieces of functionality that can be independently developed, deployed, and scaled. This modern practice of software development allows teams to build faster, reduce costs, and limit downtime.
In this blog post, we'll get a taste for how serverless computing can allow us to quickly develop and deploy applications. We'll use AWS Lambda as our serverless platform and MongoDB Atlas as our database provider.
Let's get to it.
To follow along with this tutorial, you'll need the following:
- Node.js 12
MongoDB Atlas can be used for FREE with a M0 sized cluster. Deploy MongoDB in minutes within the MongoDB Cloud. Learn more about the Atlas Free Tier cluster here.
#My First AWS Lambda Serverless Function
AWS Lambda is Amazon's serverless computing platform and is one of the leaders in the space. To get started with AWS Lambda, you'll need an Amazon Web Services account, which you can sign up for free if you don't already have one.
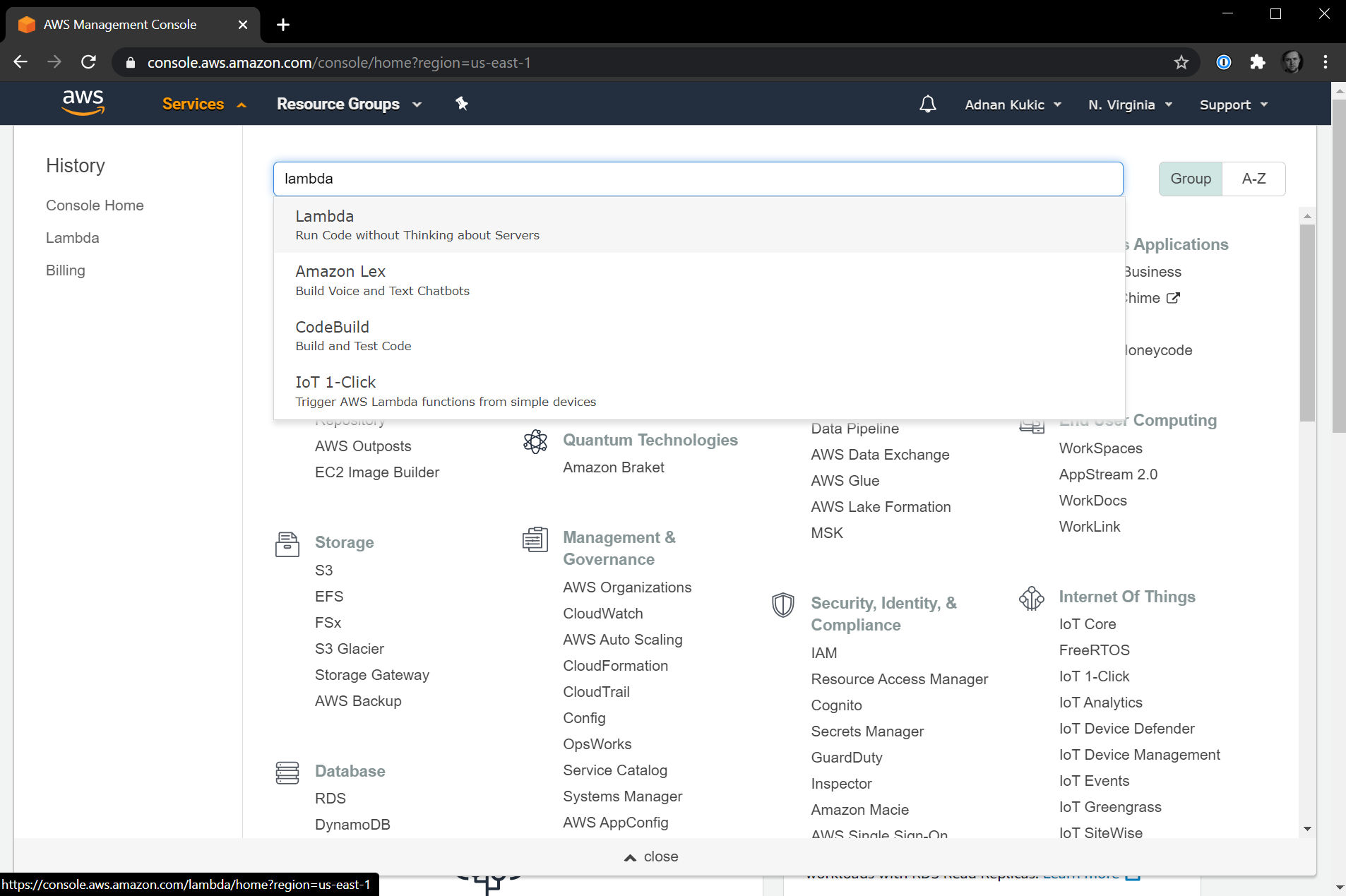
Once you are signed up and logged into the AWS Management Console, to find the AWS Lambda service, navigate to the Services top-level menu and in the search field type "Lambda", then select "Lambda" from the dropdown menu.
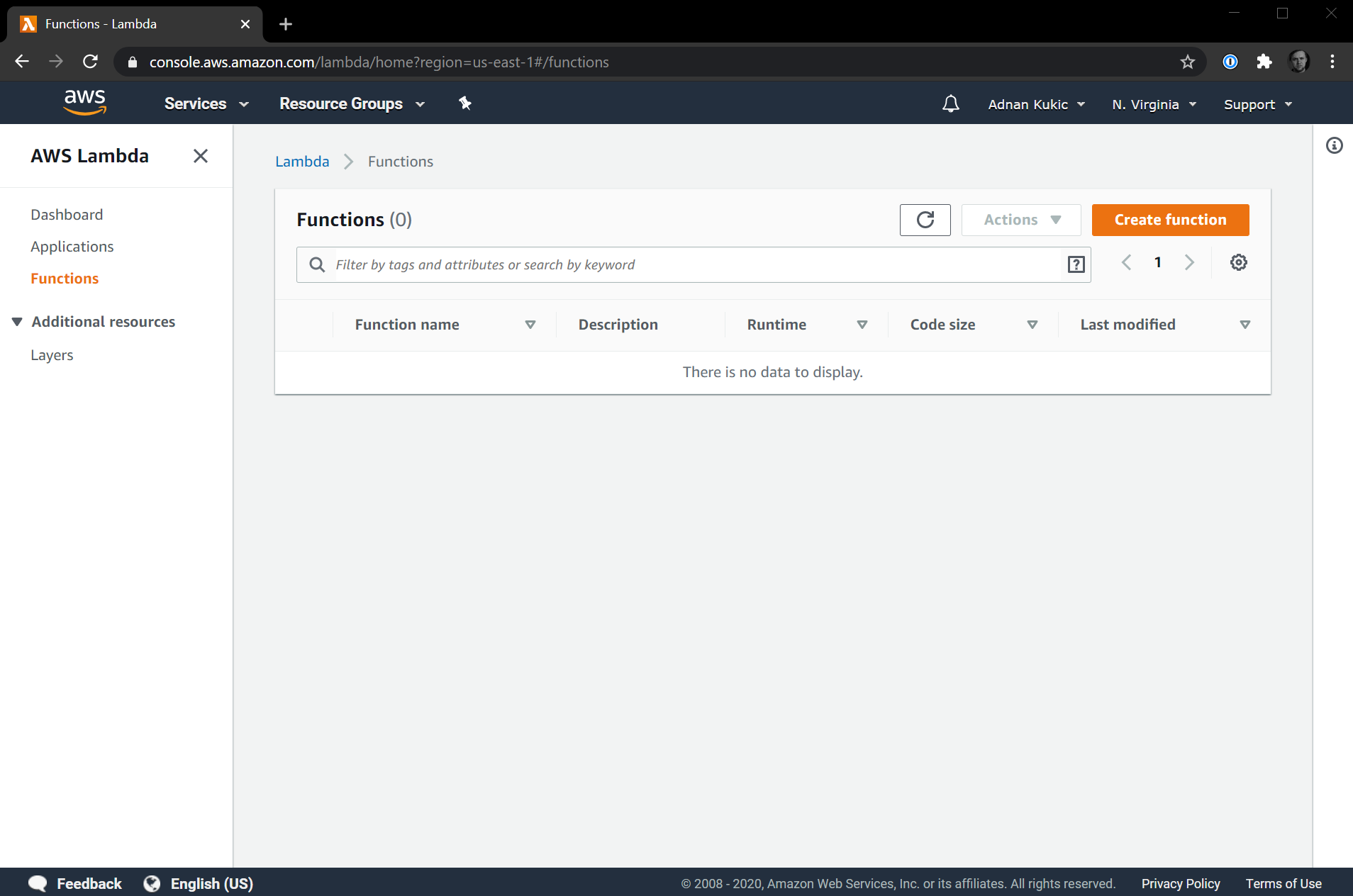
You will be taken to the AWS Lambda dashboard. If you have a brand new account, you won't have any functions and your dashboard should look something like this:
We are ready to create our first serverless function with AWS Lambda. Let's click on the orange Create function button to get started.
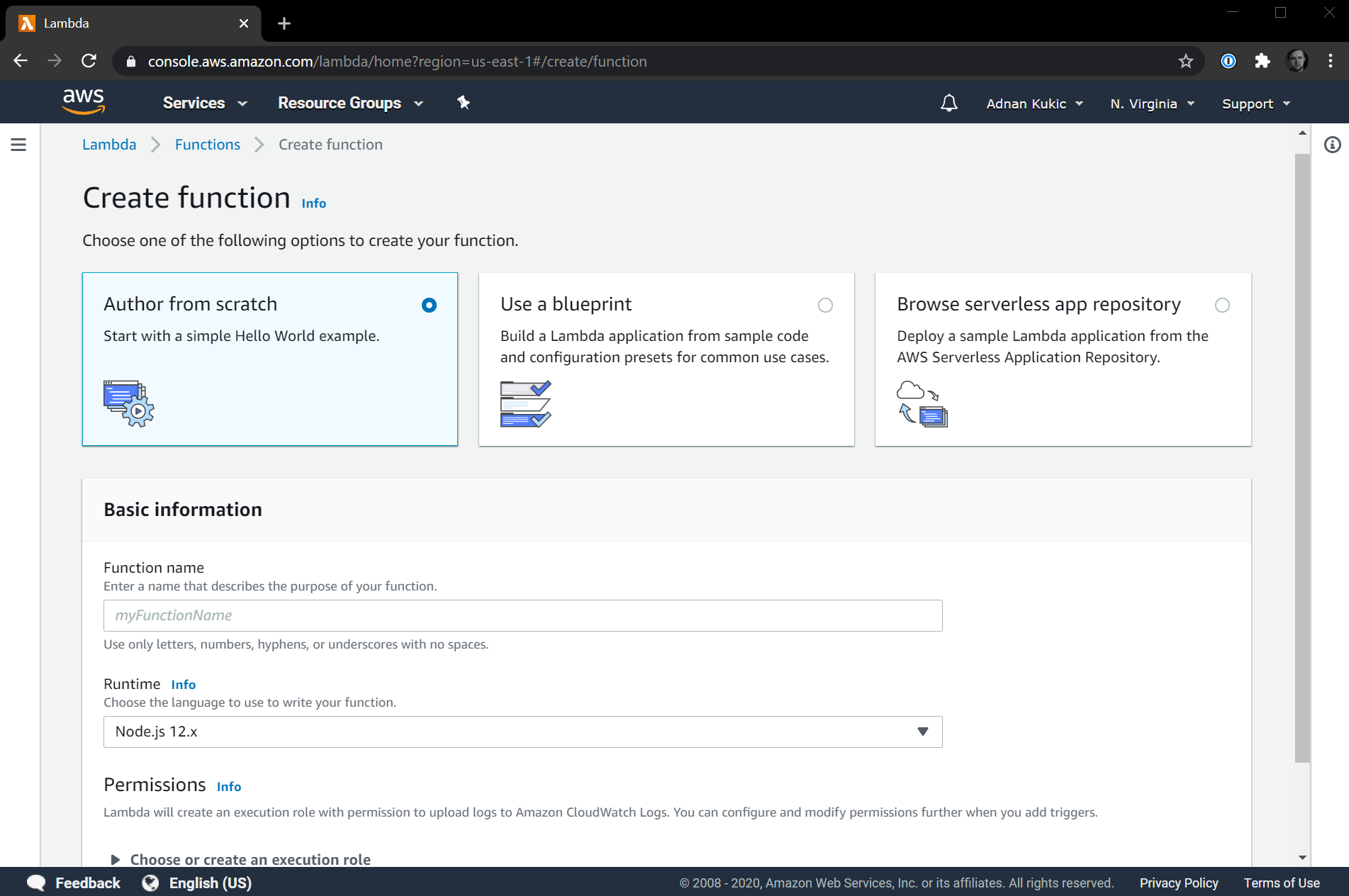
There are many different options to choose from when creating a new serverless function with AWS Lambda. We can choose to start from scratch or use a blueprint, which will have sample code already implemented for us. We can choose what programming language we want our serverless function to be written in. There are permissions to consider. All this can get overwhelming quickly, so let's keep it simple.
We'll keep all the defaults as they are, and we'll name our function myFirstFunction. Your selections should look like this:
- Function Type: Author from scratch
- Function Name: myFirstFunction
- Runtime: Node.js 12.x
- Permissions: Create a new role with basic Lambda permissions.
With these settings configured, hit the orange Create function button to create your first AWS Lambda serverless function. This process will take a couple of seconds, but once your function is created you will be greeted with a new screen that looks like this:
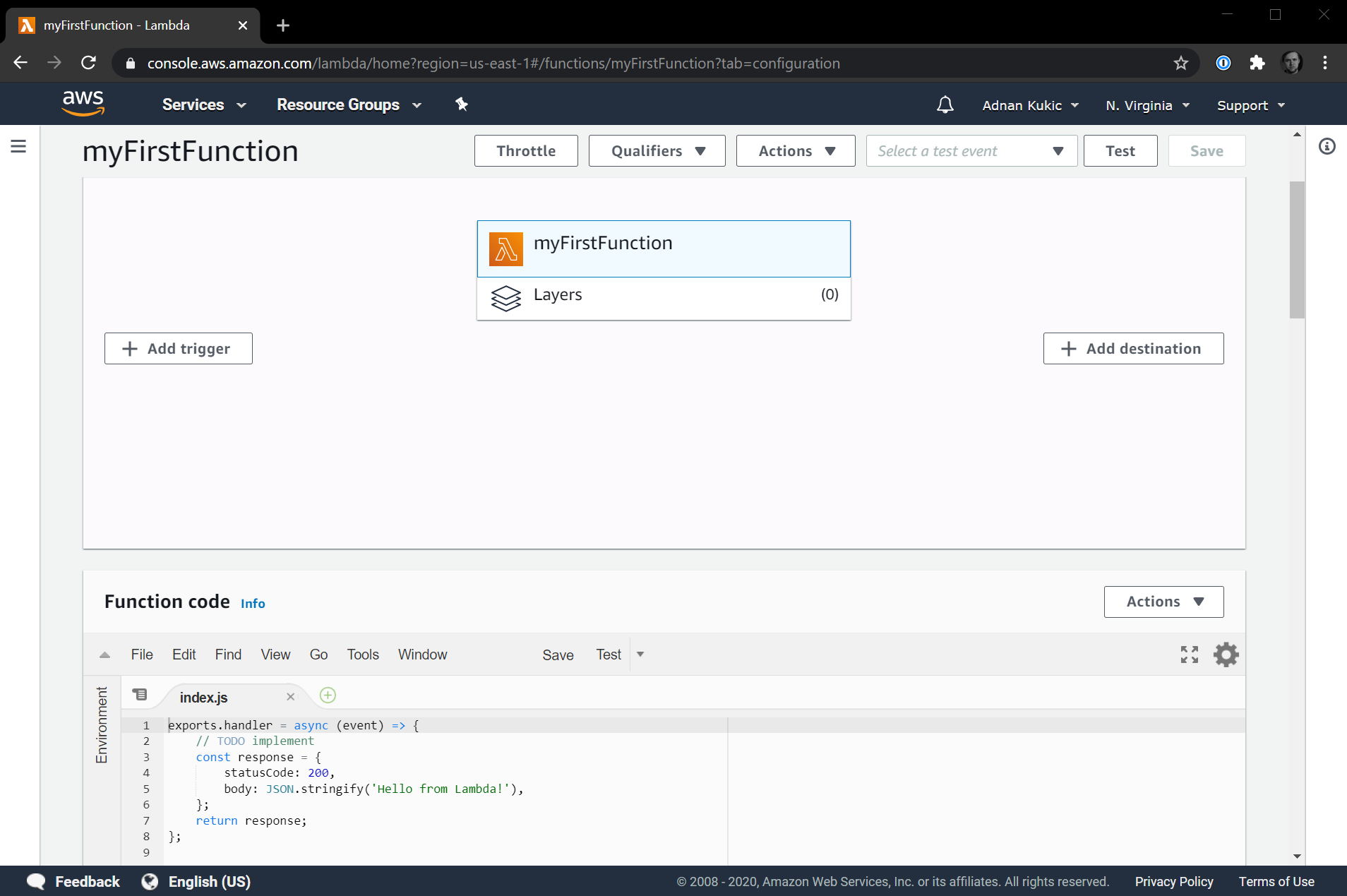
Let's test out our function to make sure that it runs. If we scroll down to the Function code section and take a look at the current code it should look like this:
1 exports.handler = async (event) => { 2 // TODO implement 3 const response = { 4 statusCode: 200, 5 body: JSON.stringify('Hello from Lambda!'), 6 }; 7 return response; 8 };
Let's hit the Test button to execute the code and make sure it runs. Hitting the Test button the first time will ask us to configure a test event. We can keep all the defaults here, but we will need to name our event. Let's name it RunFunction and then hit the Create button to create the test event. Now click the Test button again and the code editor will display the function's execution results.
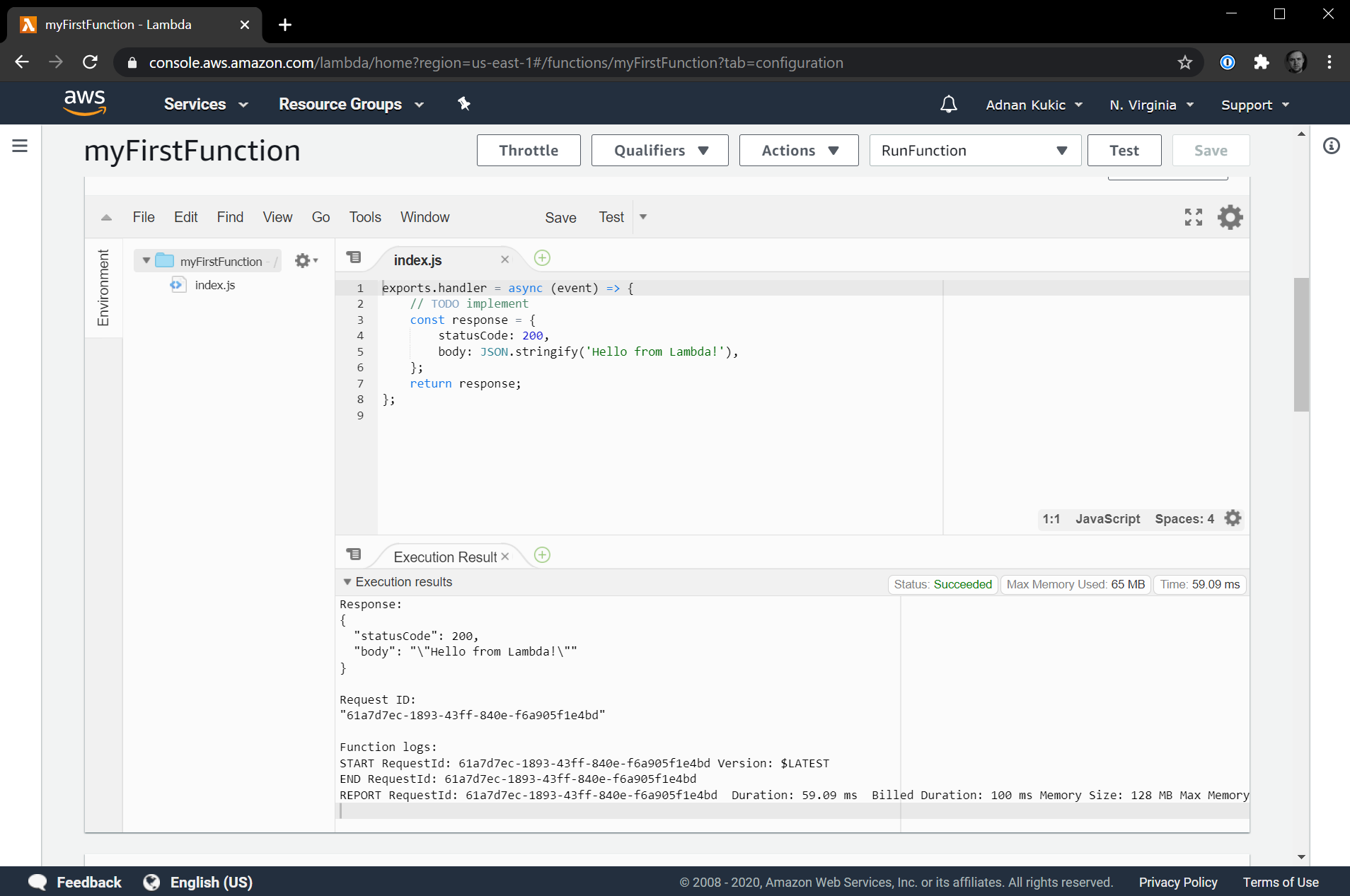
We got a successful response with a message saying "Hello from Lambda!" Let's make an edit to our function. Let's change the message to "My First Serverless Function!!!". Once you've made this edit, hit the Save button and the serverless function will be re-deployed. The next time you hit the Test button you'll get the updated message.
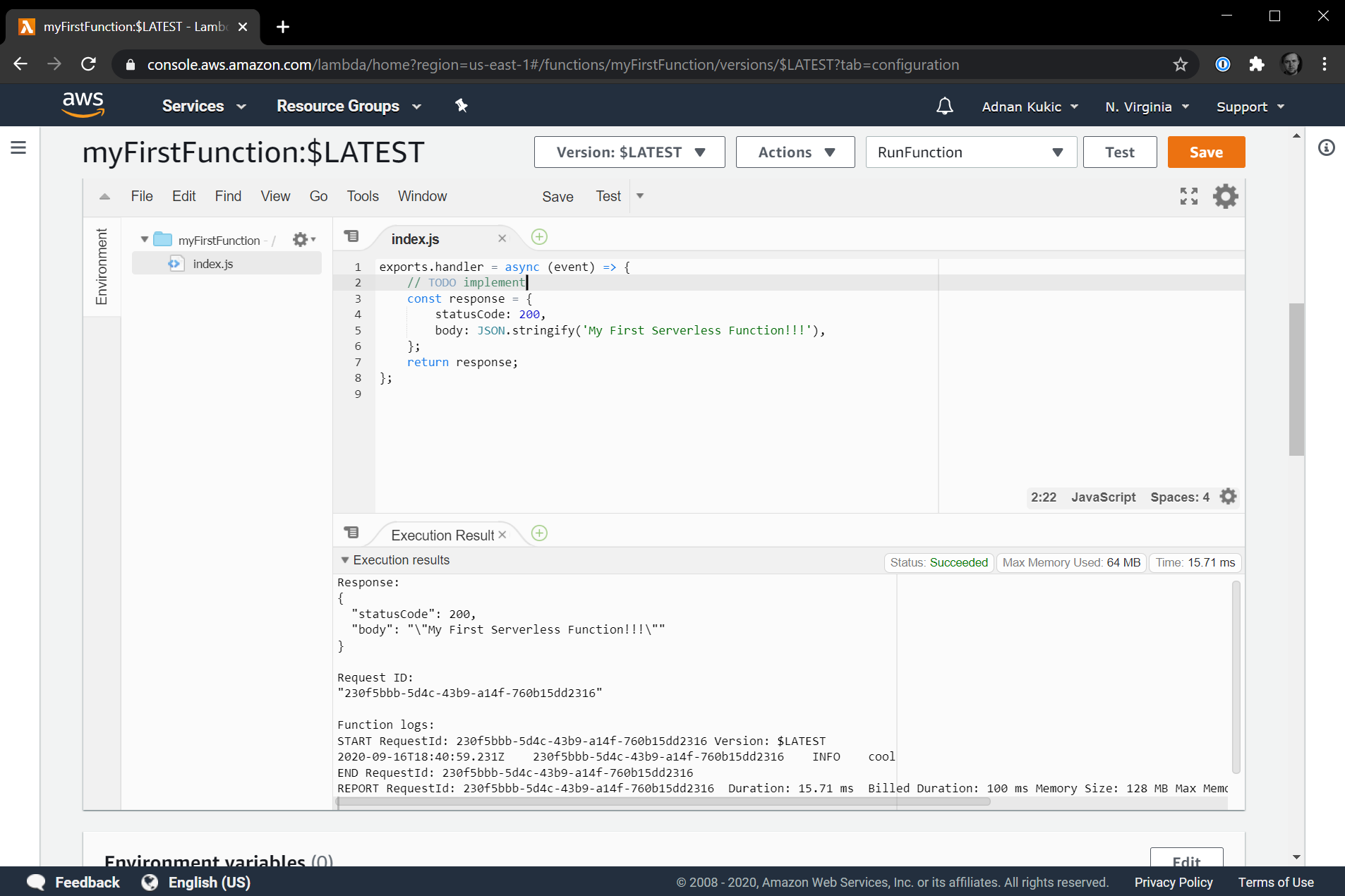
This is pretty great. We are writing Node.js code in the cloud and having it update as soon as we hit the save button. Although our function doesn't do a whole lot right now, our AWS Lambda function is not exposed to the Internet. This means that the functionality we have created cannot be consumed by anyone. Let's fix that next.
We'll use AWS API Gateway to expose our AWS Lambda function to the Internet. To do this, scroll up to the top of the page and hit the Add Trigger button in the Designer section of the page.
In the trigger configuration dropdown menu we'll select API Gateway (It'll likely be the first option). From here, we'll select Create an API and for the type, choose HTTP API. To learn about the differences between HTTP APIs and REST APIs, check out this AWS docs page. For security, we'll select Open as securing the API endpoint is out of the scope of this article. We can leave all other options alone and just hit the Add button to create our API Gateway.
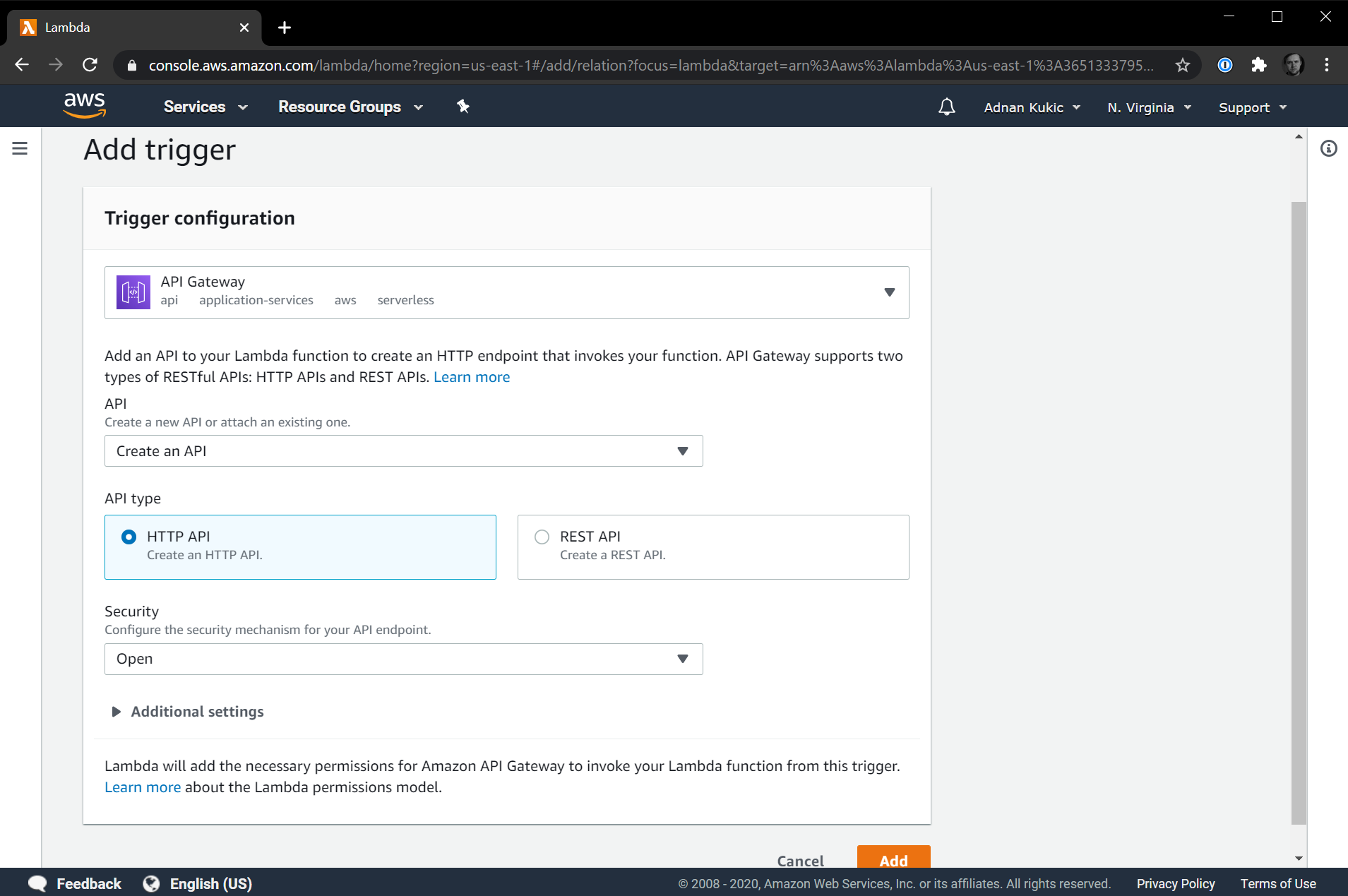
Within a couple of seconds, we should see our Designer panel updated to include the API Gateway we created. Clicking on the API Gateway and opening up details will give us additional information including the URL where we can now call our serverless function from our browser.
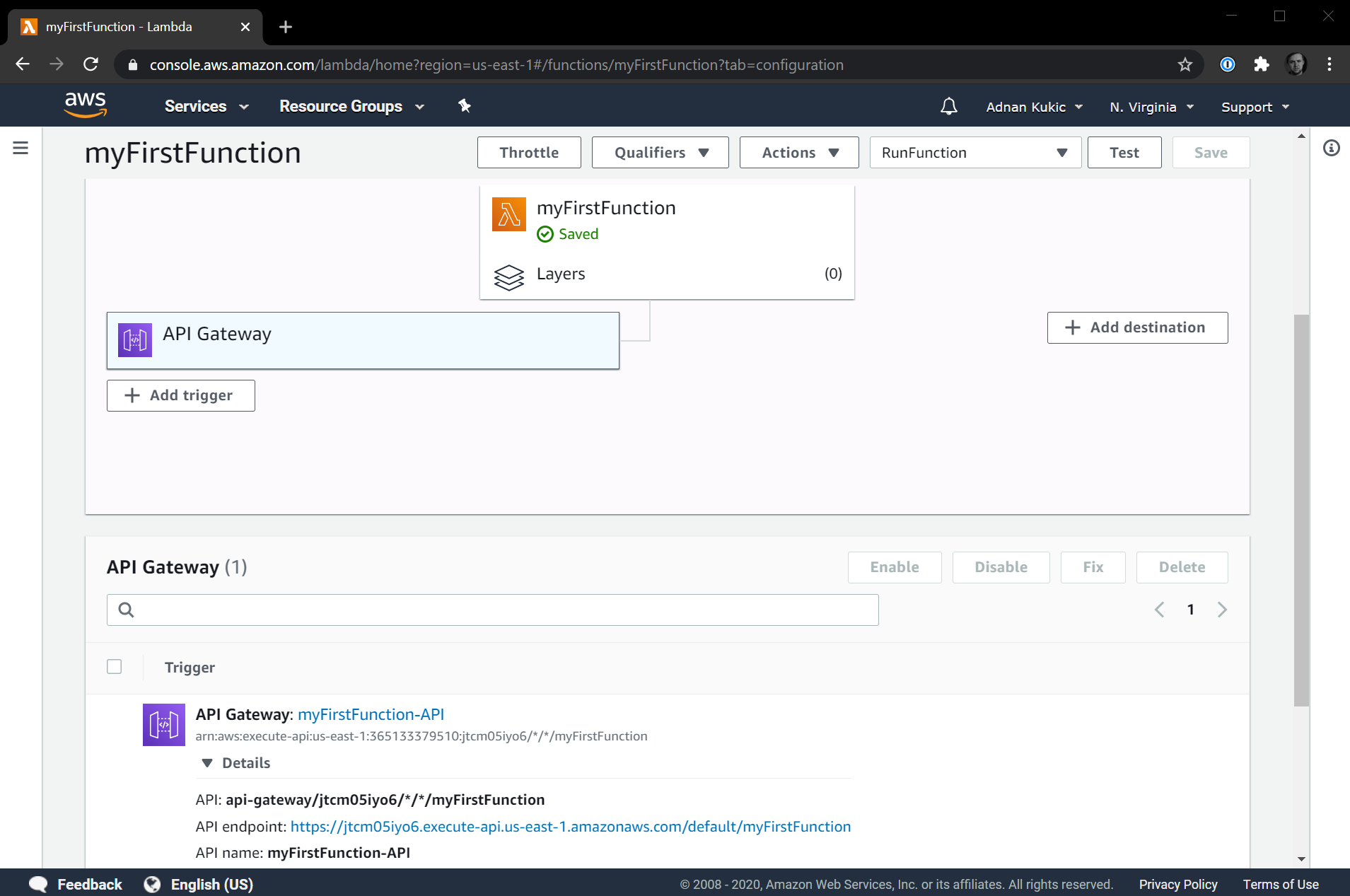
In my case, the URL is https://jtcm05iyo6.execute-api.us-east-1.amazonaws.com/default/myFirstFunction. Navigating to this URL displays the response you'd expect:

Note: If you click the above live URL, you'll likely get a different result, as it'll reflect a change made later in this tutorial.
We're making great progress. We've created, deployed, and exposed a AWS Lambda serverless function to the Internet. Our function doesn't do much though. Let's work on that next. Let's add some real functionality to our serverless function.
Unfortunately, the online editor at present time does not allow you to manage dependencies or run scripts, so we'll have to shift our development to our local machine. To keep things concise, we'll do our development from now on locally. Once we're happy with the code, we'll zip it up and upload it to AWS Lambda.
This is just one way of deploying our code and while not necessarily the most practical for a real world use case, it'll make our tutorial easier to follow as we won't have to manage the extra steps of setting up the AWS CLI or deploying our code to GitHub and using GitHub Actions to deploy our AWS Lambda functions. These options are things you should explore when deciding to build actual applications with serverless frameworks as they'll make it much easier to scale your apps in the long run.
To set up our local environment let's create a new folder that we'll use to store our code. Create a folder and call it myFirstFunction. In this folder create two files: index.js and package.json. For the package.json file, for now let's just add the following:
1 { 2 "name": "myFirstFunction", 3 "version": "1.0.0", 4 "dependencies": { 5 "faker" : "latest" 6 } 7 }
The package.json file is going to allow us to list dependencies for our applications. This is something that we cannot do at the moment in the online editor. The Node.js ecosystem has a plethora of packages that will allow us to easily bring all sorts of functionality to our apps. The current package we defined is called faker and is going to allow us to generate fake data. You can learn more about faker on the project's GitHub Page. To install the faker dependency in your myFirstFunction folder, run npm install. This will download the faker dependency and store it in a node_modules folder.
We're going to make our AWS Lambda serverless function serve a list of movies. However, since we don't have access to real movie data, this is where faker comes in. We'll use faker to generate data for our function. Open up your index.js file and add the following code:
1 const faker = require("faker"); 2 3 exports.handler = async (event) => { 4 // TODO implement 5 const movie = { 6 title: faker.lorem.words(), 7 plot: faker.lorem.paragraph(), 8 director: `${faker.name.firstName()} ${faker.name.lastName()}`, 9 image: faker.image.abstract(), 10 }; 11 const response = { 12 statusCode: 200, 13 body: JSON.stringify(movie), 14 }; 15 return response; 16 };
With our implementation complete, we're ready to upload this new code to our AWS Lambda serverless function. To do this, we'll first need to zip up the contents within the myFirstFunction folder. The way you do this will depend on the operating system you are running. For Mac, you can simply highlight all the items in the myFirstFunction folder, right click and select Compress from the menu. On Windows, you'll highlight the contents, right click and select Send to, and then select Compressed Folder to generate a single .zip file. On Linux, you can open a shell in myFirstFunction folder and run zip aws.zip *.
NOTE: It's very important that you zip up the contents of the folder, not the folder itself. Otherwise, you'll get an error when you upload the file.
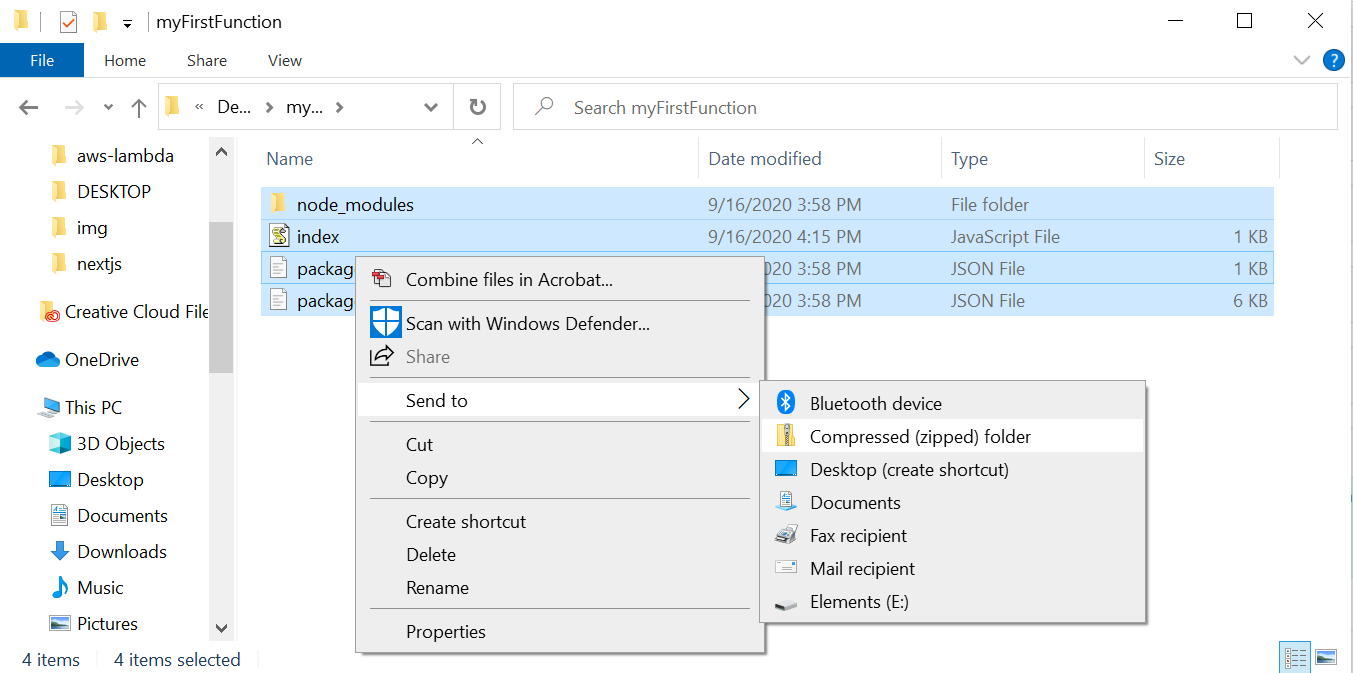
Once we have our folder zipped up, it's time to upload it. Navigate to the Function code section of your AWS Lambda serverless function and this time, rather than make code changes directly in the editor, click on the Actions button in the top right section and select Upload a .zip file.
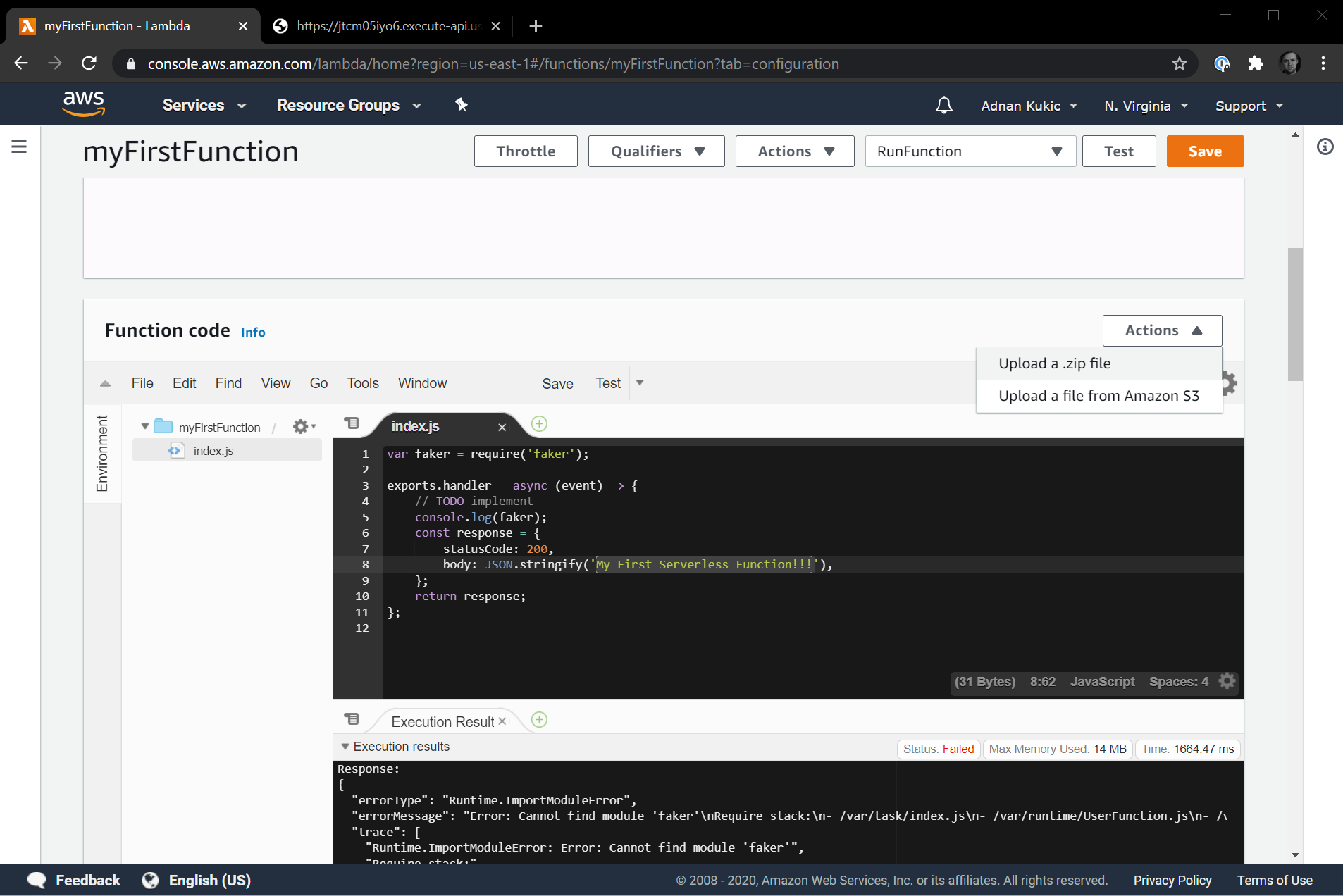
Select the compressed file you created and upload it. This may take a few seconds. Once your function is uploaded, you'll likely see a message that says The deployment package of your Lambda function "myFirstFunction" is too large to enable inline code editing. However, you can still invoke your function. This is ok. The faker package is large, and we won't be using it for much longer.
Let's test it. We'll test it in within the AWS Lambda dashboard by hitting the Test button at the top.
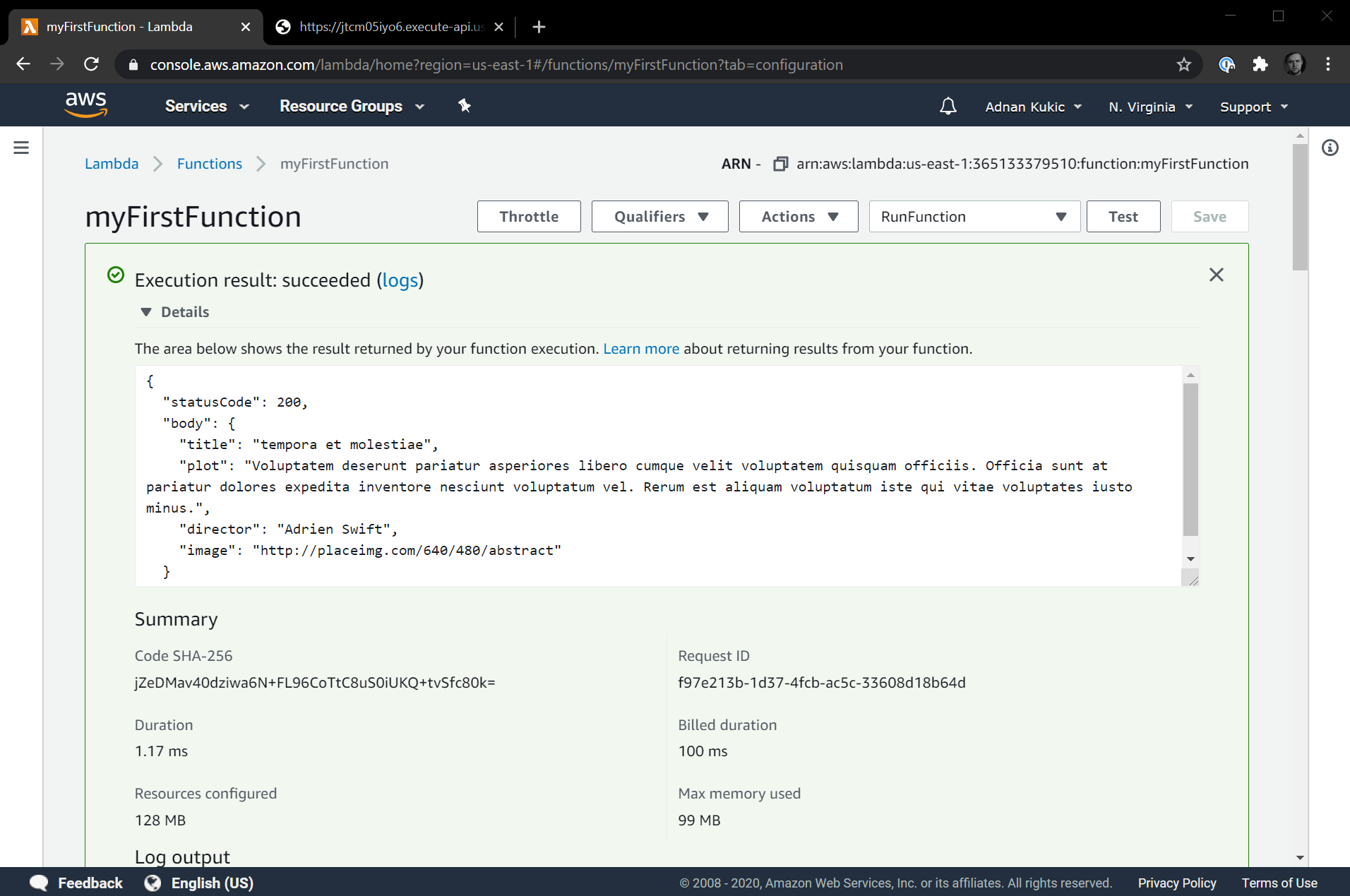
We are getting a successful response! The text is a bunch of lorem ipsum but that's what we programmed the function to generate. Every time you hit the test button, you'll get a different set of data.
#Getting Up and Running with MongoDB Atlas
Generating fake data is fine, but let's step our game up and serve real movie data. For this, we'll need access to a database that has real data we can use. MongoDB Atlas has multiple free datasets that we can utilize and one of them just happens to be a movie dataset.
Let's start by setting up our MongoDB Atlas account. If you don't already have one, sign up for one here.
MongoDB Atlas can be used for FREE with a M0 sized cluster. Deploy MongoDB in minutes within the MongoDB Cloud.
When you are signed up and logged into the MongoDB Atlas dashboard, the first thing we'll do is set up a new cluster. Click the Build a Cluster button to get started.
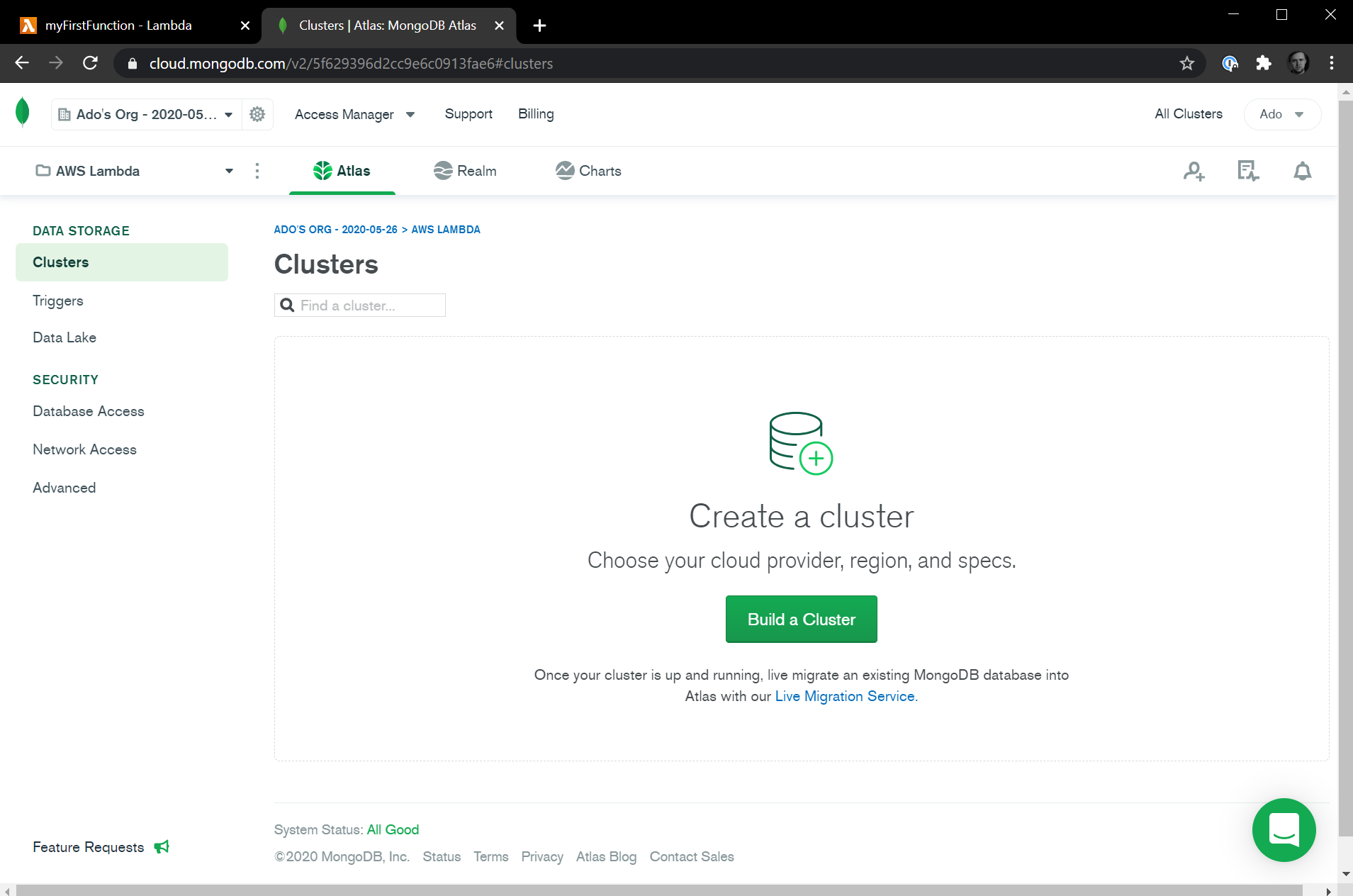
From here, select the Shared Clusters option, which will have the free tier we want to use.
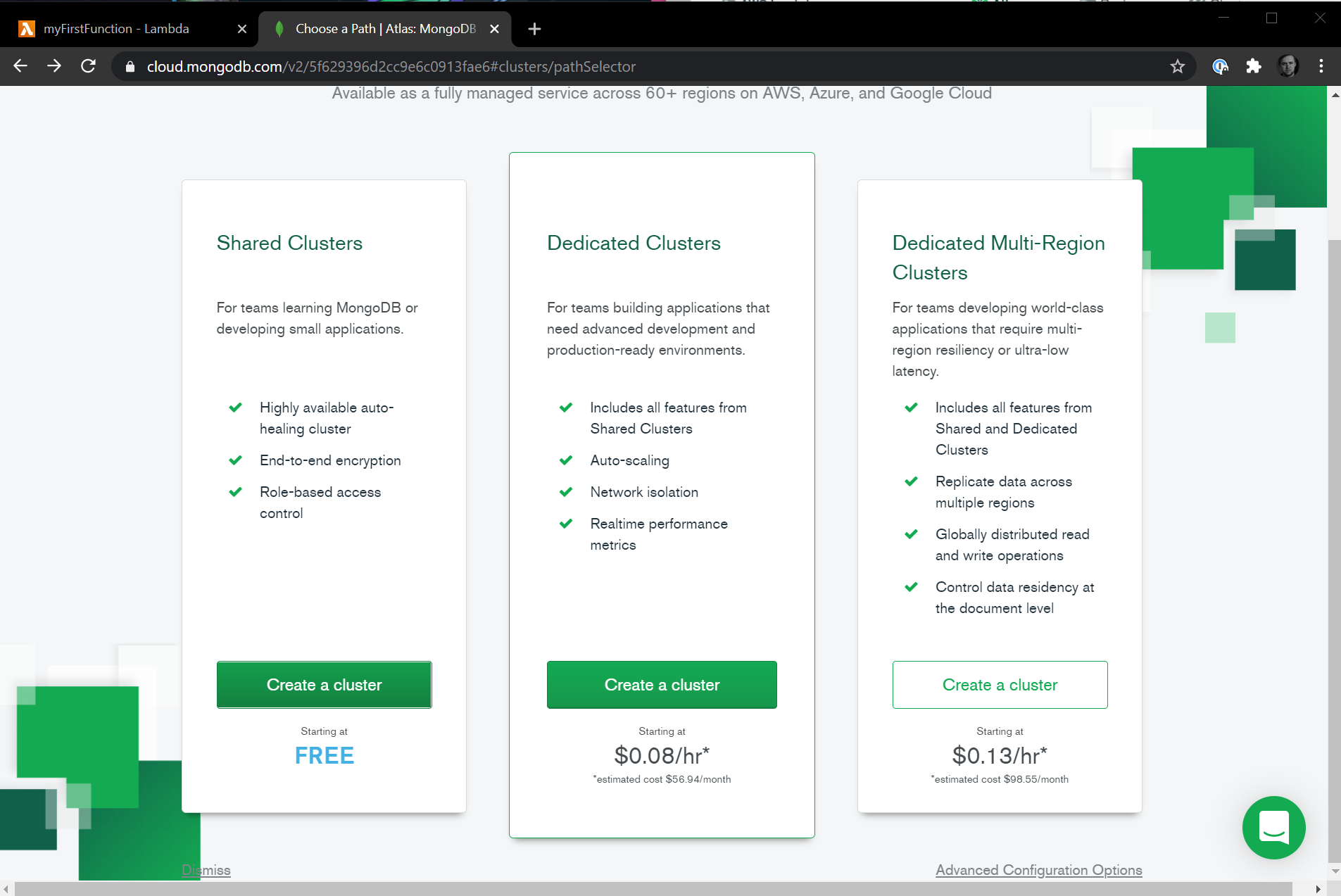
Finally, for the last selection, you can leave all the defaults as is and just hit the green Create Cluster button at the bottom. Depending on your location, you may want to choose a different region, but I'll leave everything as is for the tutorial. The cluster build out will take about a minute to deploy.
While we wait for the cluster to be deployed, let's navigate to the Database Access tab in the menu and create a new database user. We'll need a database user to be able to connect to our MongoDB database. In the Database Access page, click on the Add New Database User button and give your user a unique username and password. Be sure to write these down as you'll need them soon enough. Ensure that this database user can read and write to any database by checking the Database User Privileges dropdown. It should be selected by default, but if it's not, ensure that it's set to Read and write to any database.
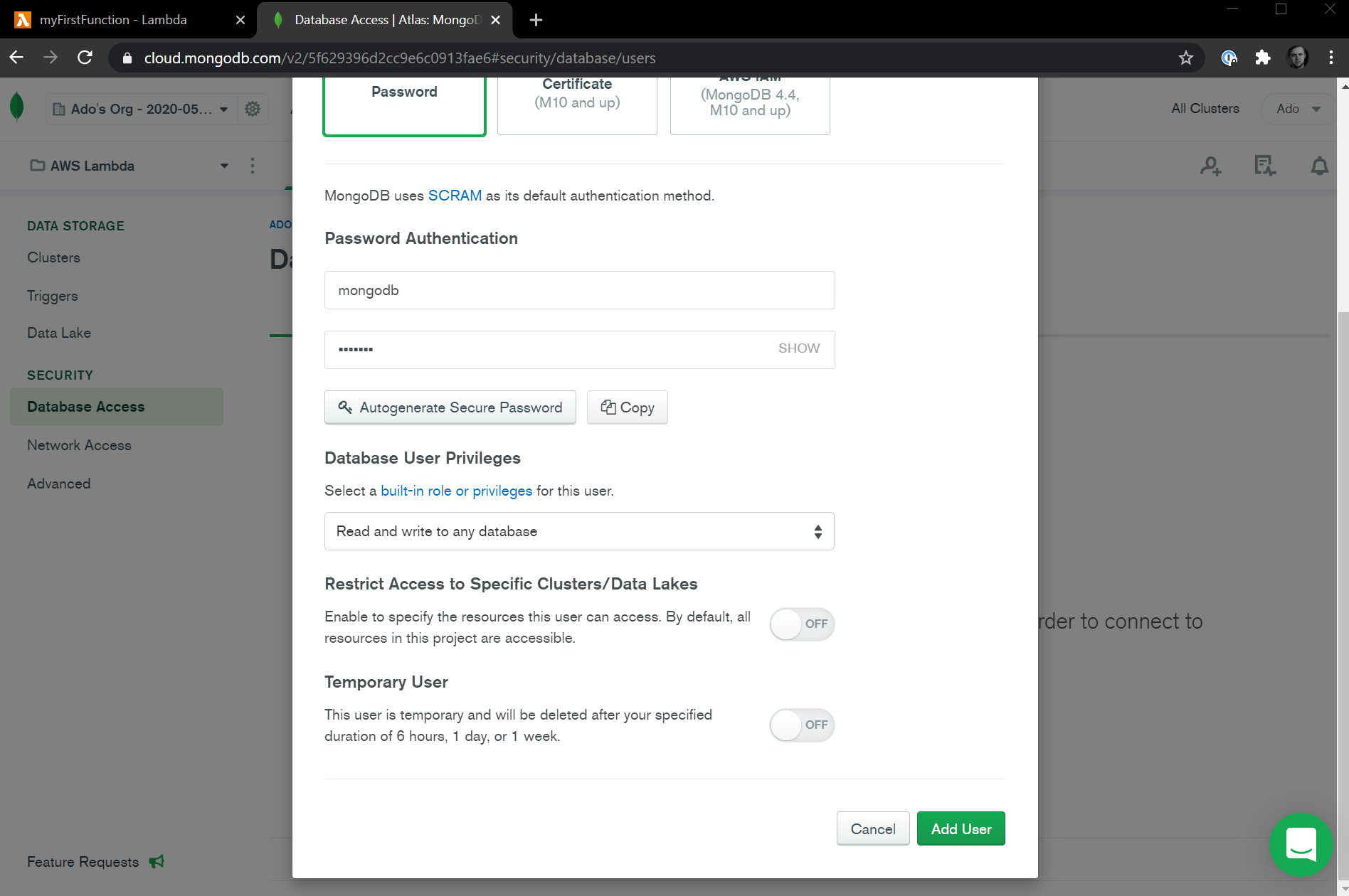
Next, we'll also want to configure network access by navigating to the Network Access tab in the dashboard. For the sake of this tutorial, we'll enable access to our database from any IP as long as the connection has the correct username and password. In a real world scenario, you'll want to limit database access to specific IPs that your application lives on, but configuring that is out of scope for this tutorial.
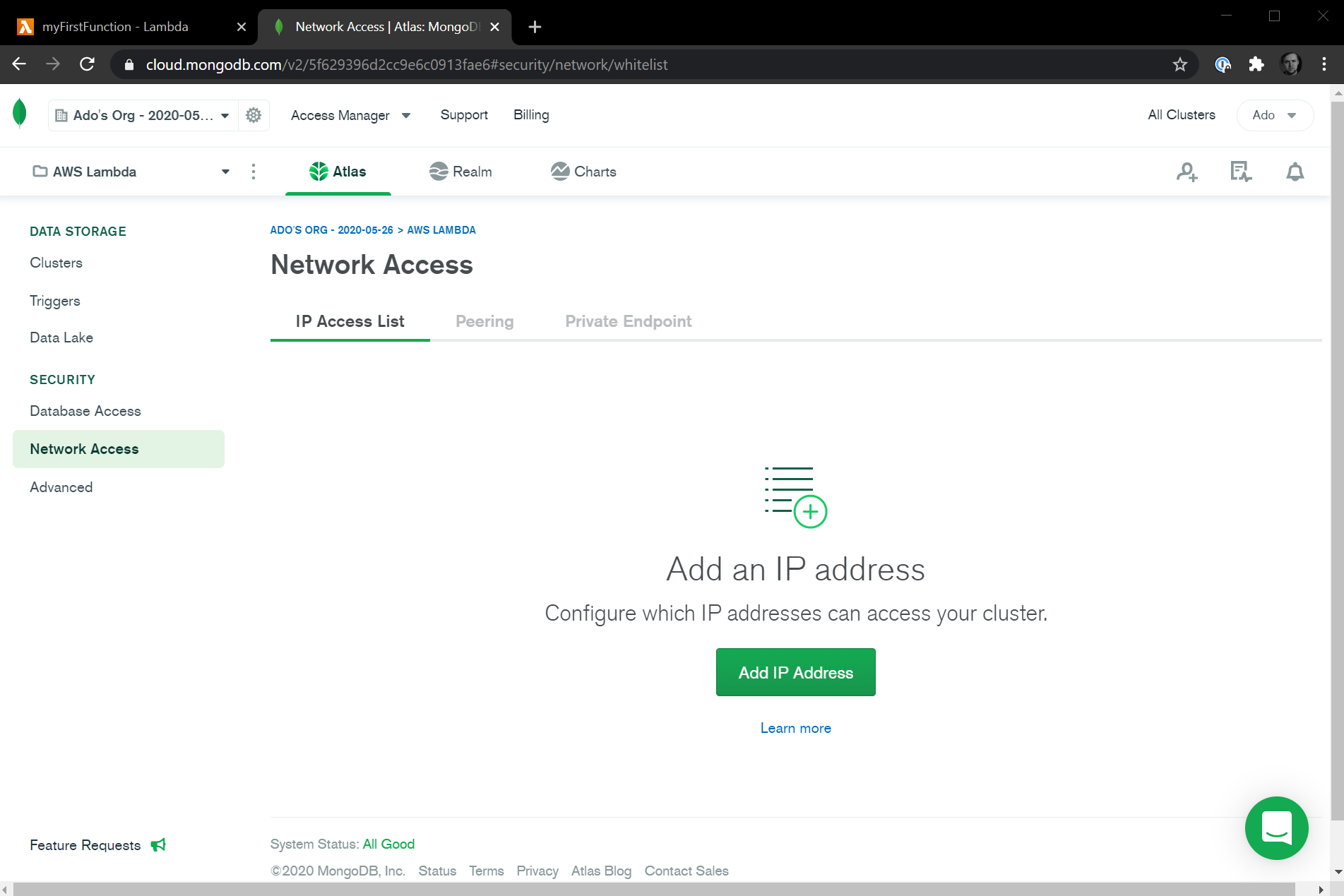
Click on the green Add IP Address button, then in the modal that pops up click on Allow Access From Anywhere. Click the green Confirm button to save the change.
By now our cluster should be deployed. Let's hit the Clusters selection in the menu and we should see our new cluster created and ready to go. It will look like this:
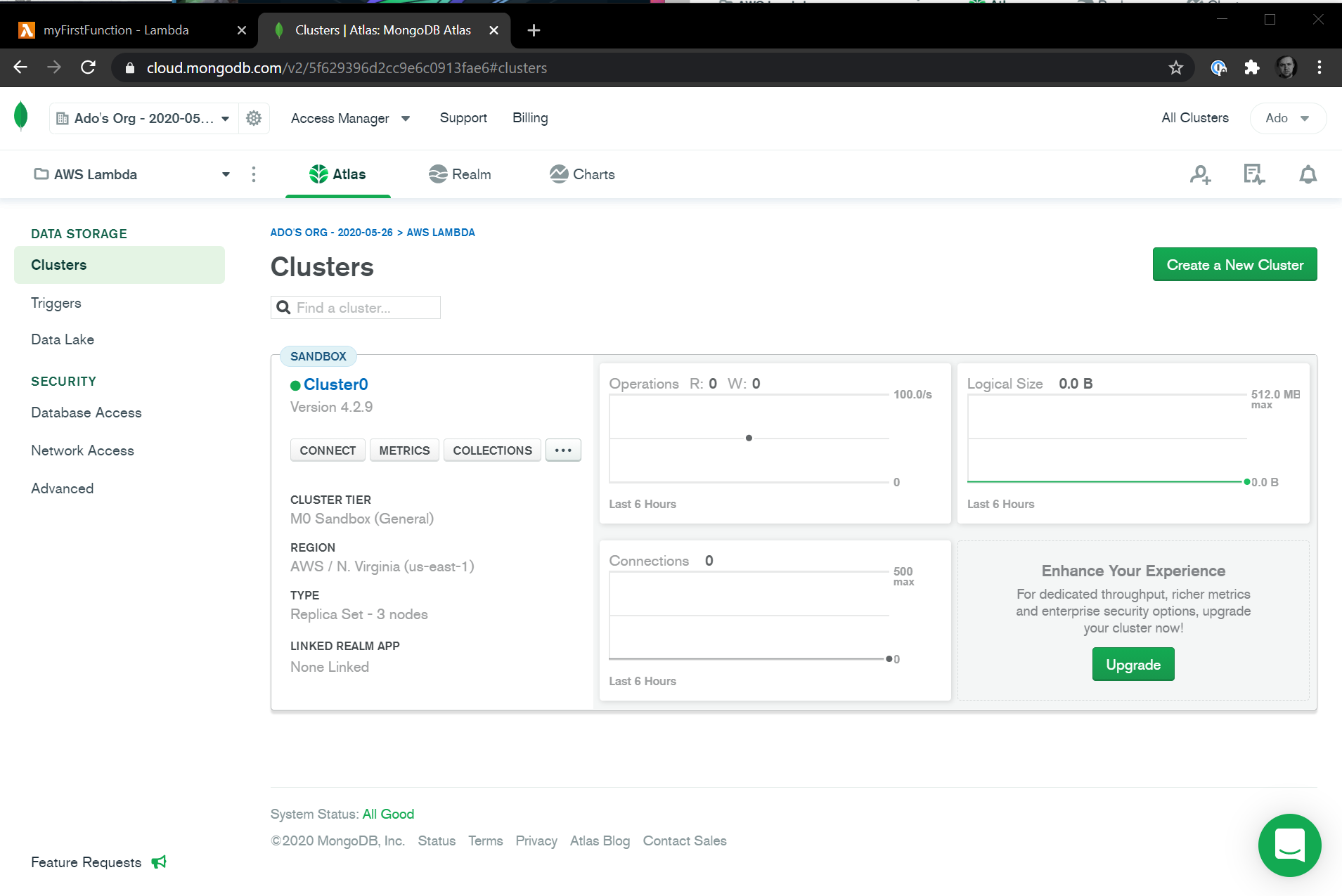
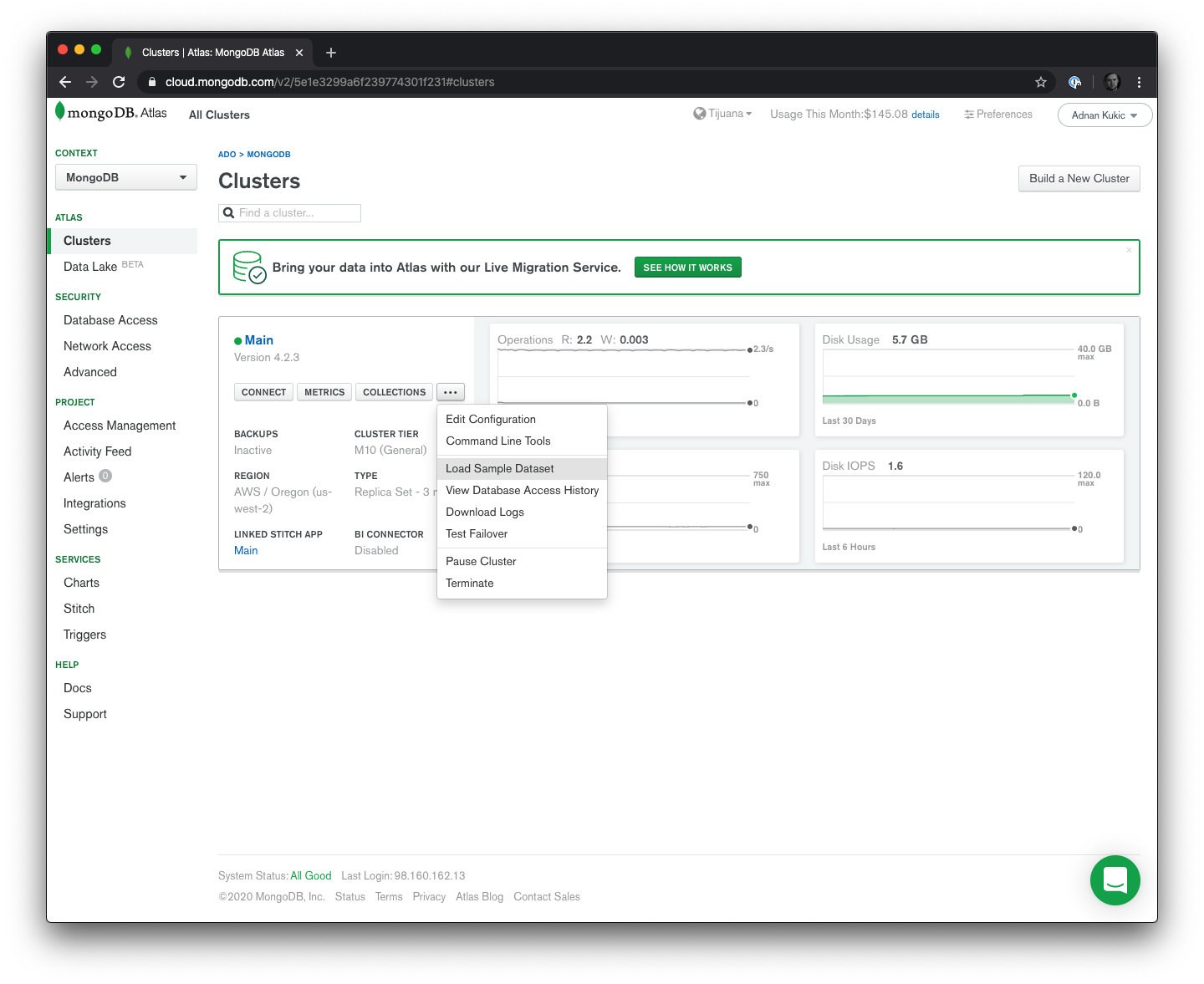
One final thing we'll need to do is add our sample datasets. To do this, click on the ... button in your cluster and select the Load Sample Dataset option. Confirm in the modal that you want to load the data and the sample dataset will be loaded.
After the sample dataset is loaded, let's click the Collections button in our cluster to see the data. Once the Collections tab is loaded, from the databases section, select the sample_mflix database, and the movies collection within it. You'll see the collection information at the top and the first twenty movies displayed on the right. We have our dataset!
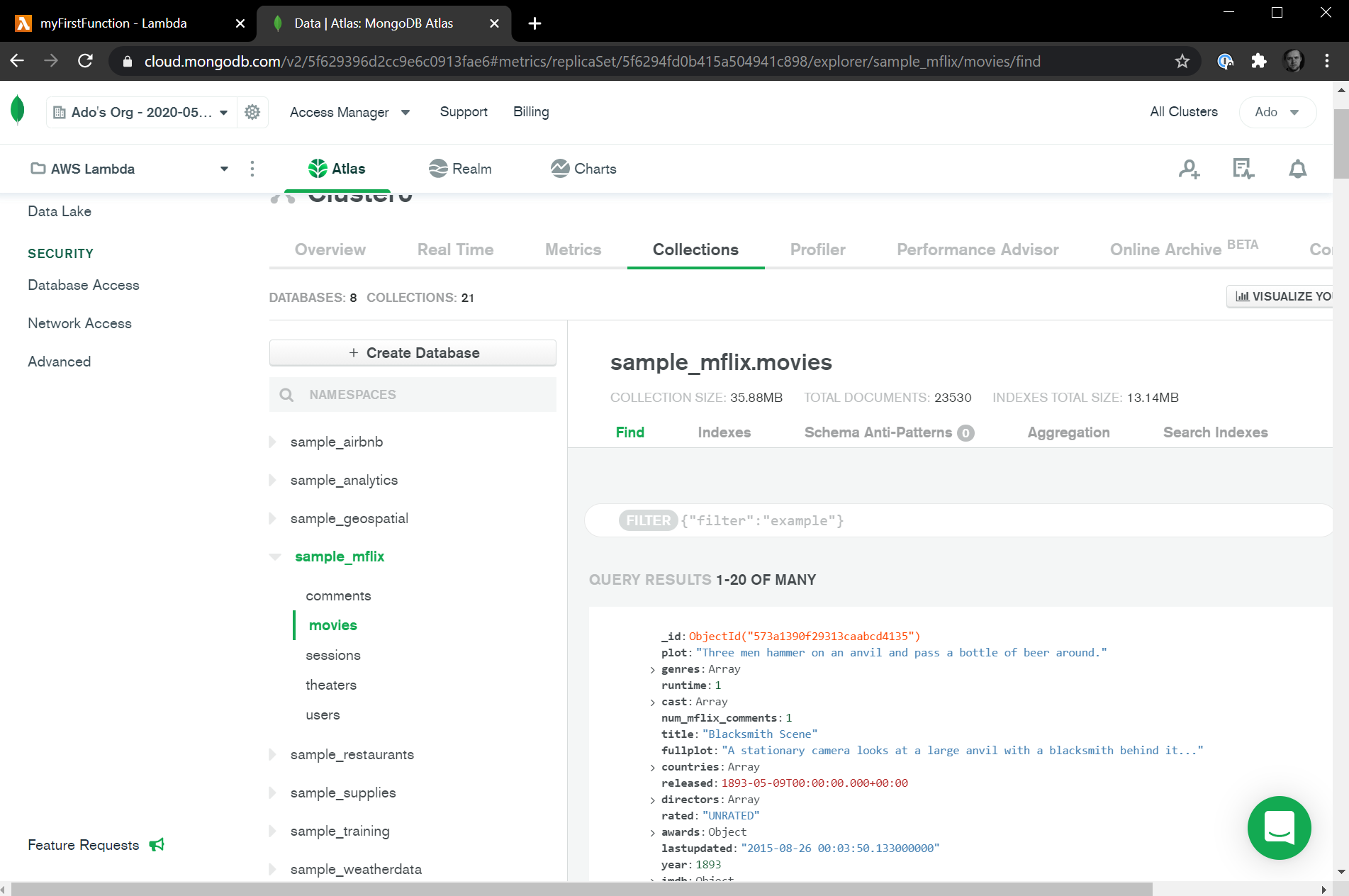
Next, let's connect our MongoDB databases that's deployed on MongoDB Atlas to our Serverless AWS Lambda function.
#Connecting MongoDB Atlas to AWS Lambda
We have our database deployed and ready to go. All that's left to do is connect the two. On our local machine, let's open up the package.json file and add mongodb as a dependency. We'll remove faker as we'll no longer use it for our movies.
1 { 2 "name": "myFirstFunction", 3 "version": "1.0.0", 4 "dependencies": { 5 "mongodb": "latest" 6 } 7 }
Then, let's run npm install to install the MongoDB Node.js Driver in our node_modules folder.
Next, let's open up index.js and update our AWS Lambda serverless function. Our code will look like this:
1 // Import the MongoDB driver 2 const MongoClient = require("mongodb").MongoClient; 3 4 // Define our connection string. Info on where to get this will be described below. In a real world application you'd want to get this string from a key vault like AWS Key Management, but for brevity, we'll hardcode it in our serverless function here. 5 const MONGODB_URI = 6 "mongodb+srv://<USERNAME>:<PASSWORD>@cluster0.cvaeo.mongodb.net/test?retryWrites=true&w=majority"; 7 8 // Once we connect to the database once, we'll store that connection and reuse it so that we don't have to connect to the database on every request. 9 let cachedDb = null; 10 11 async function connectToDatabase() { 12 if (cachedDb) { 13 return cachedDb; 14 } 15 16 // Connect to our MongoDB database hosted on MongoDB Atlas 17 const client = await MongoClient.connect(MONGODB_URI); 18 19 // Specify which database we want to use 20 const db = await client.db("sample_mflix"); 21 22 cachedDb = db; 23 return db; 24 } 25 26 exports.handler = async (event, context) => { 27 28 /* By default, the callback waits until the runtime event loop is empty before freezing the process and returning the results to the caller. Setting this property to false requests that AWS Lambda freeze the process soon after the callback is invoked, even if there are events in the event loop. AWS Lambda will freeze the process, any state data, and the events in the event loop. Any remaining events in the event loop are processed when the Lambda function is next invoked, if AWS Lambda chooses to use the frozen process. */ 29 context.callbackWaitsForEmptyEventLoop = false; 30 31 // Get an instance of our database 32 const db = await connectToDatabase(); 33 34 // Make a MongoDB MQL Query to go into the movies collection and return the first 20 movies. 35 const movies = await db.collection("movies").find({}).limit(20).toArray(); 36 37 const response = { 38 statusCode: 200, 39 body: JSON.stringify(movies), 40 }; 41 42 return response; 43 };
The MONGODB_URI is your MongoDB Atlas connection string. To get this value, head over to your MongoDB Atlas dashboard. On the Clusters overview page, click on the Connect button.
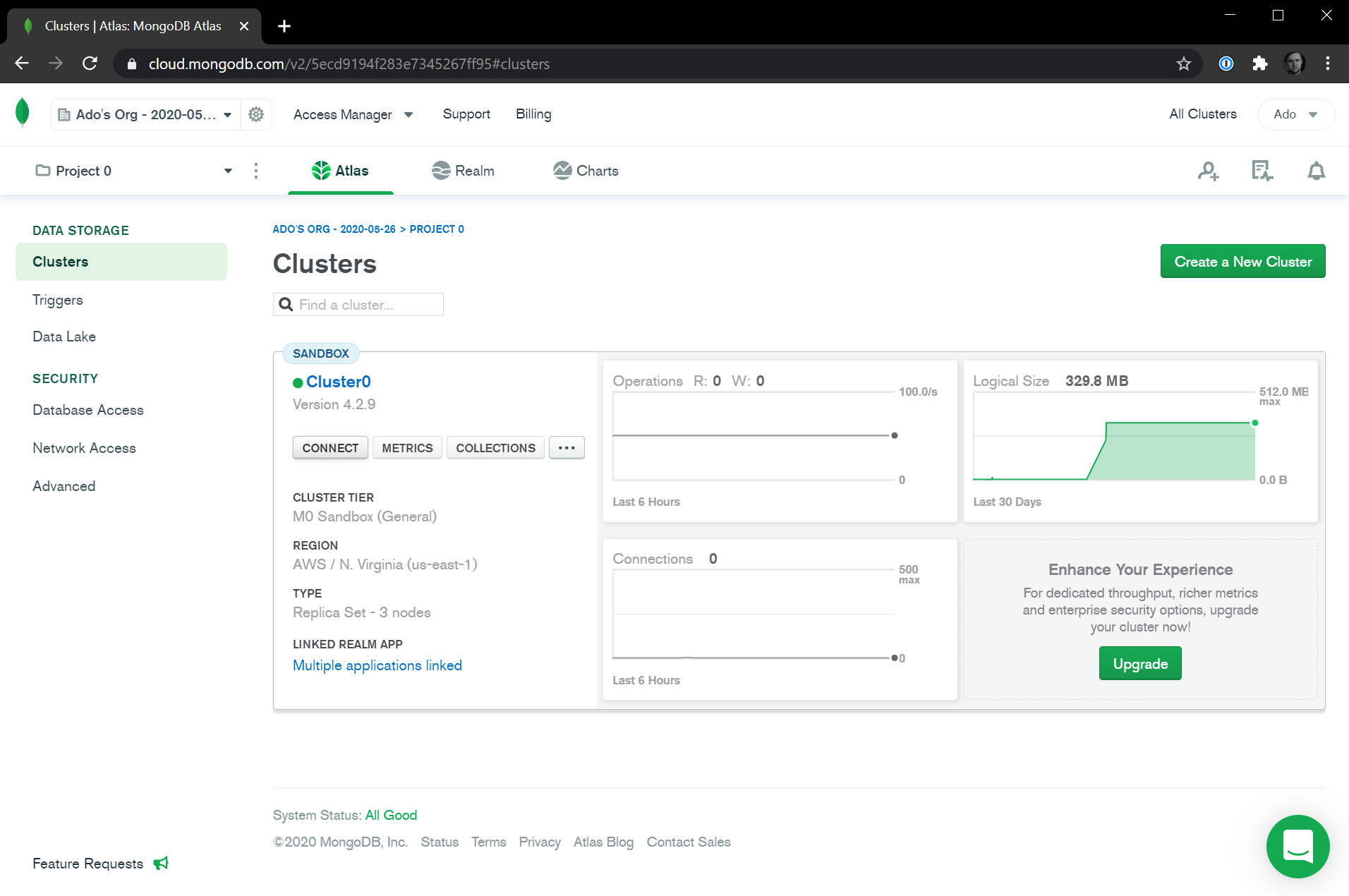
From here, select the Connect your application option and you'll be taken to a screen that has your connection string. Note: Your username will be pre-populated, but you'll have to update the password and dbname values.
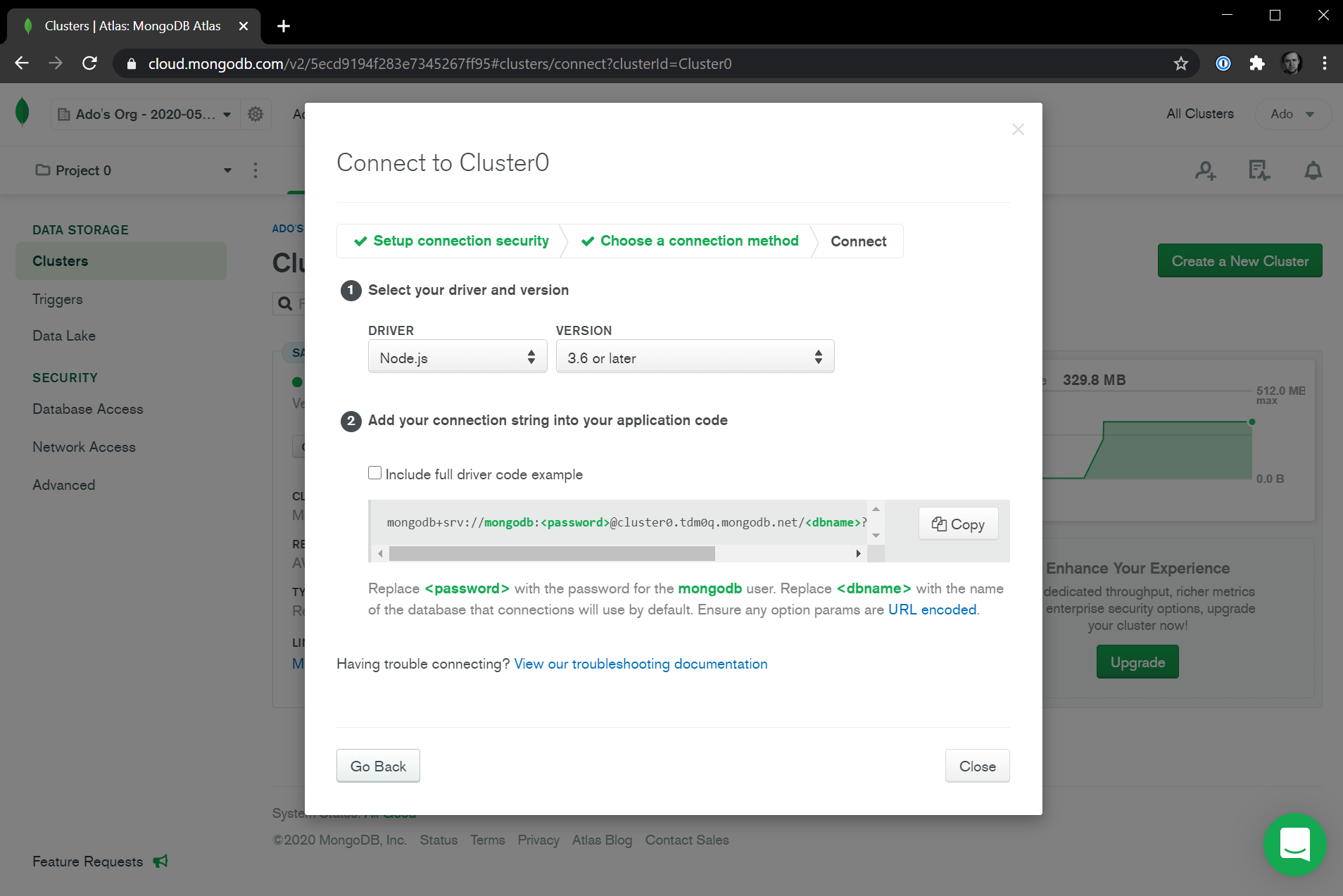
Once you've made the above updates to your index.js file, save it, and zip up the contents of your myFirstFunction folder again. We'll redeploy this code, by going back to our AWS Lambda function and uploading the new zip file. Once it's uploaded, let's test it by hitting the Test button at the top right of the page.
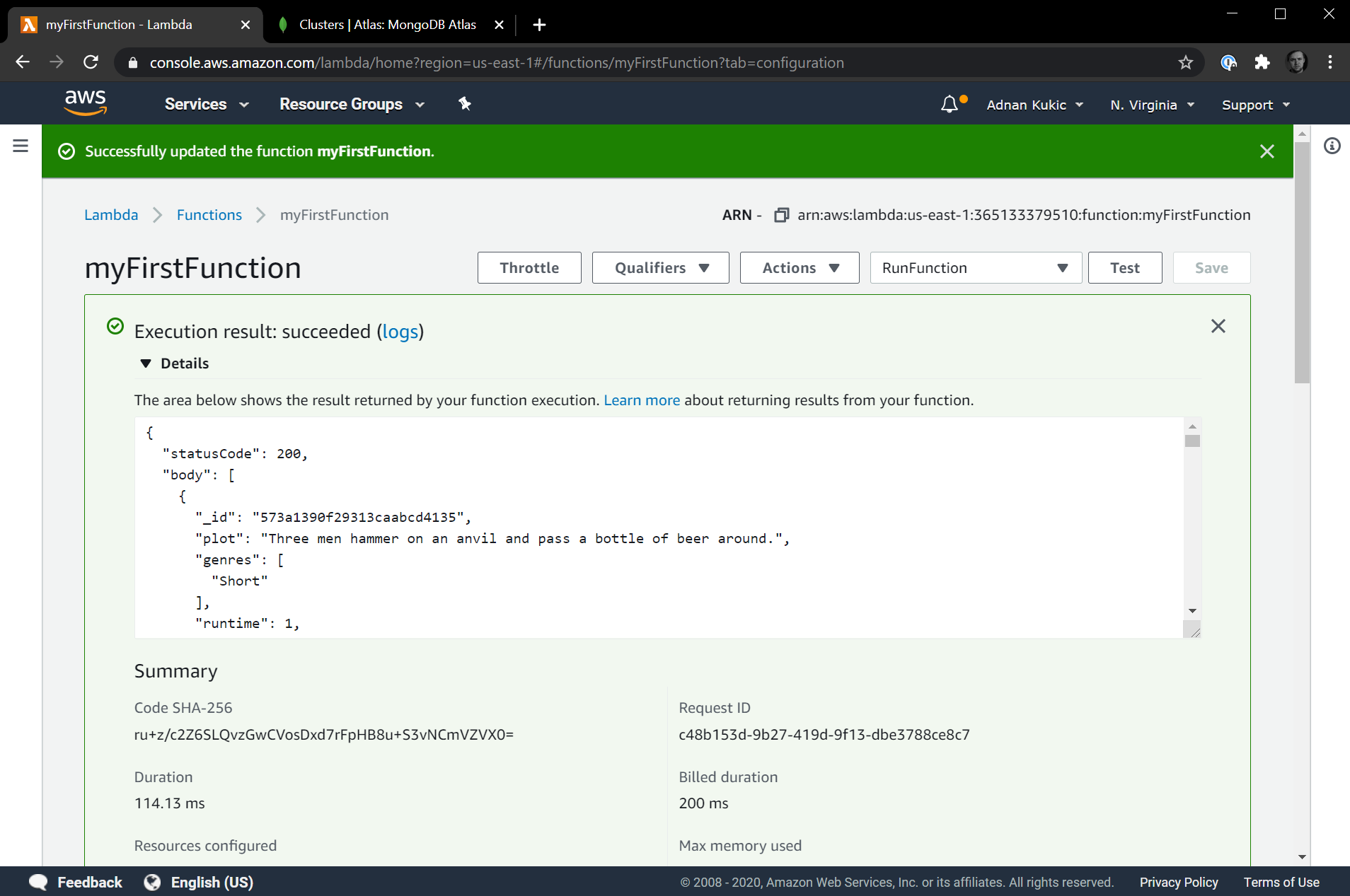
It works! We get a list of twenty movies from our sample_mflix MongoDB database that is deployed on MongoDB Atlas.
We can also call our function directly by going to the API Gateway URL from earlier and seeing the results in the browser as well. Navigate to the API Gateway URL you were provided and you should see the same set of results. If you need a refresher on where to find it, navigate to the Designer section of your AWS Lambda function, click on API Gateway, click the Details button to expand all the information, and you'll see an API Endpoint URL which is where you can publicly access this serverless function.
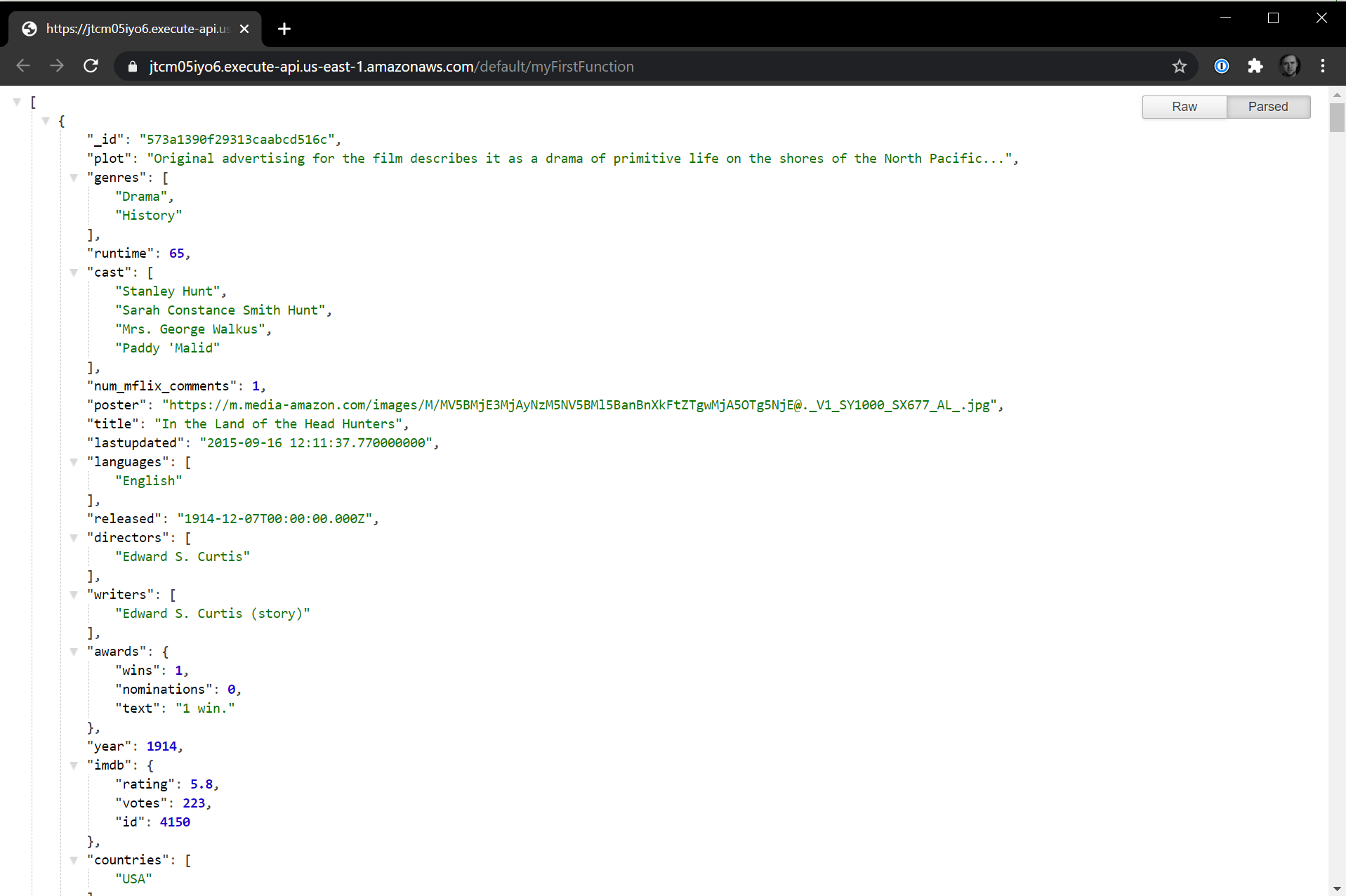
The query that we have written returns a list of twenty movies from our sample_mflix.movies collection. You can modify this query to return different types of data easily. Since this file is much smaller, we're able to directly modify it within the browser using the AWS Lambda online code editor. Let's change our query around so that we get a list of twenty of the highest rated movies and instead of getting back all the data on each movie, we'll just get back the movie title, plot, rating, and cast. Replace the existing query which looks like:
1 const movies = await db.collection("movies").find({}).limit(20).toArray();
To:
1 const movies = await db.collection("movies").find({},{projection: {title: 1, plot: 1, metacritic: 1, cast:1}}).sort({metacritic: -1}).limit(20).toArray()
Our results will look slightly different now. The first result we get now is The Wizard of Oz which has a Metacritic rating of 100.
#One More Thing...
We created our first AWS Lambda serverless function and we made quite a few modifications to it. With each iteration we changed the functionality of what the function is meant to do, but generally we settled on this function retrieving data from our MongoDB database.
To close out this article, let's quickly create another serverless function, this one to add data to our movies collection. Since we've already become pros in the earlier section, this should go much faster.
#Creating a Second AWS Lambda Function
We'll start by navigating to our AWS Lambda functions homepage. Once here, we'll see our existing function accounted for. Let's hit the orange Create function button to create a second AWS Lambda serverless function.
We'll leave all the defaults as is, but this time we'll give the function name a more descriptive name. We'll call it AddMovie.
Once this function is created, to speed things up, we'll actually upload the .zip file from our first function. So hit the Actions menu in the Function Code section, select Upload Zip File and choose the file in your myFirstFunction folder.
To make sure everything is working ok, let's create a test event and run it. We should get a list of twenty movies. If you get an error, make sure you have the correct username and password in your MONGODB_URI connection string. You may notice that the results here will not have The Wizard of Oz as the first item. That is to be expected as we made those edits within our myFirstFunction online editor. So far, so good.
Next, we'll want to capture what data to insert into our MongoDB database. To do this, let's edit our test case. Instead of the default values provided, which we do not use, let's instead create a JSON object that can represent a movie.
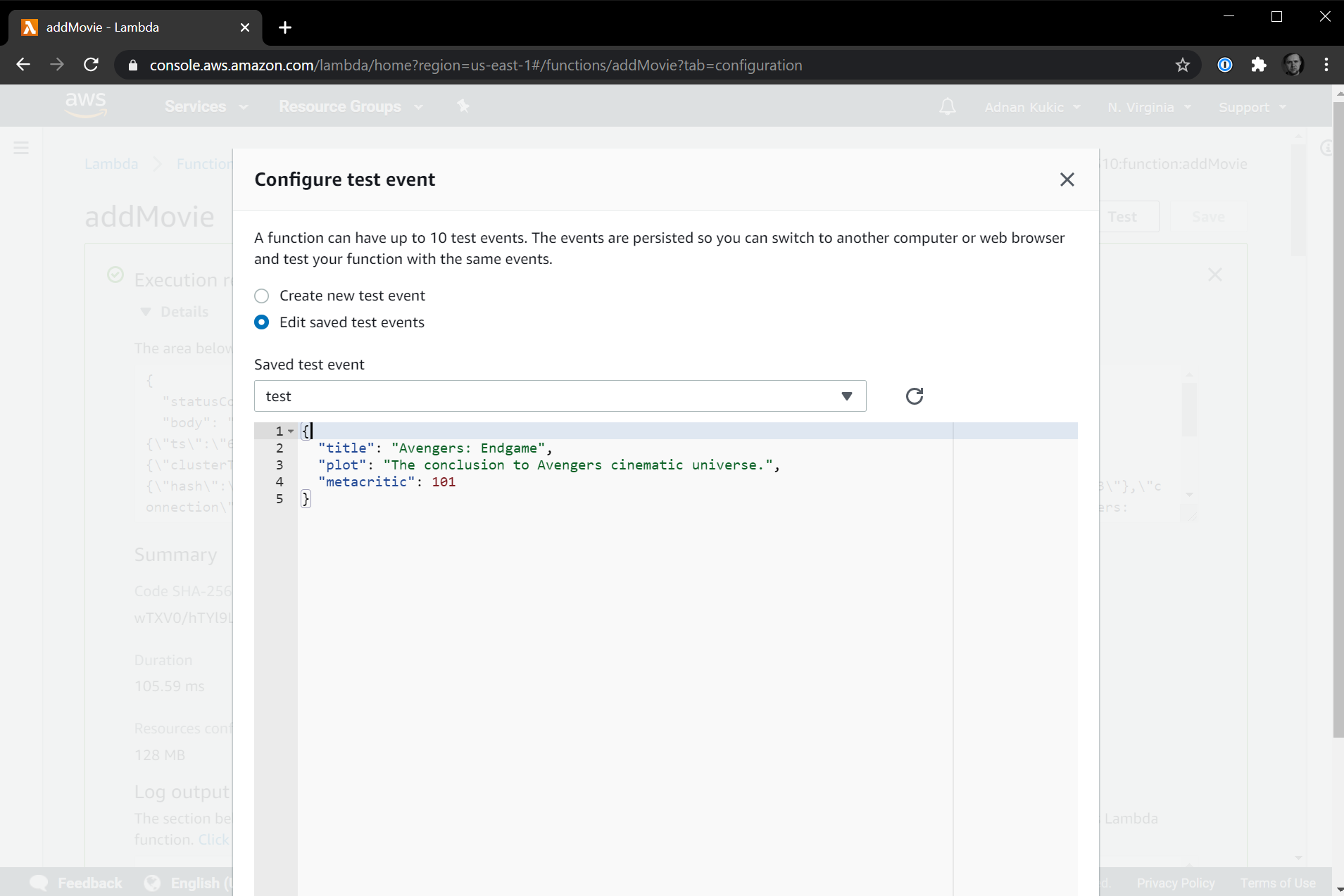
Now, let's update our serverless function to use this data and store it in our MongoDB Atlas database in the movies collection of the sample_mflix database. We are going to change our MongoDB find() query:
1 const movies = await db.collection("movies").find({}).limit(20).toArray();
To an insertOne():
1 const result = await db.collection("movies").insertOne(event);
The complete code implementation is as follows:
1 const MongoClient = require("mongodb").MongoClient; 2 const MONGODB_URI = 3 "mongodb+srv://<USERNAME>:<PASSWORD>@cluster0.cvaeo.mongodb.net/test?retryWrites=true&w=majority"; 4 5 let cachedDb = null; 6 7 async function connectToDatabase() { 8 9 if (cachedDb) { 10 return cachedDb; 11 } 12 13 const client = await MongoClient.connect(MONGODB_URI); 14 const db = await client.db('sample_mflix'); 15 cachedDb = db; 16 return db 17 } 18 19 exports.handler = async (event, context) => { 20 context.callbackWaitsForEmptyEventLoop = false; 21 22 const db = await connectToDatabase(); 23 24 // Insert the event object, which is the test data we pass in 25 const result = await db.collection("movies").insertOne(event); 26 const response = { 27 statusCode: 200, 28 body: JSON.stringify(result), 29 }; 30 31 return response; 32 };
To verify that this works, let's test our function. Hitting the test button, we'll get a response that looks like the following image:
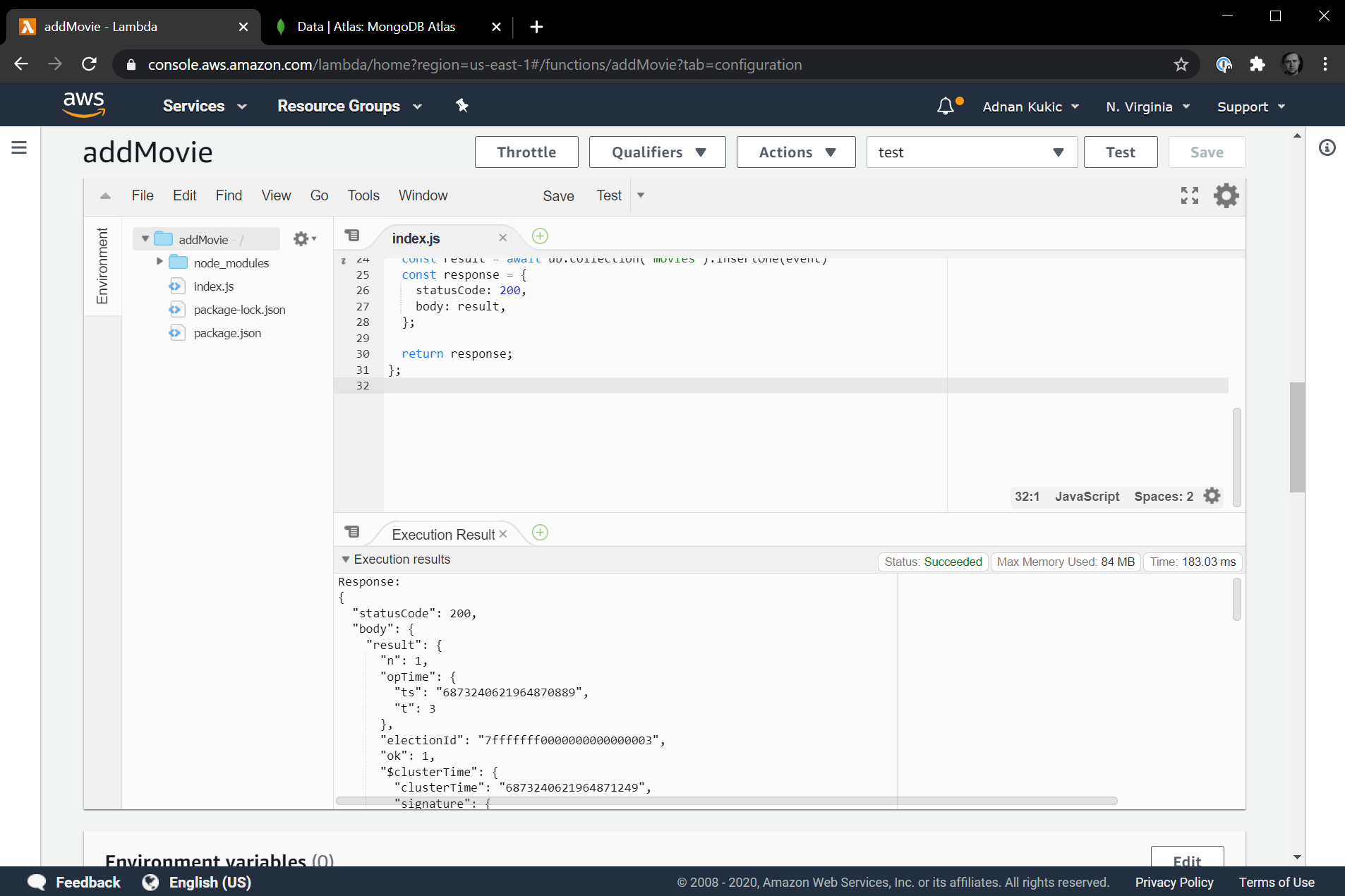
This tells us that the insert was successful. In a real world application, you probably wouldn't want to send this message to the user, but for our illustrative purposes here, it's ok. We can also confirm that the insert was successful by going into our original function and running it. Since in our test data, we set the metacritic rating to 101, this result should be the first one returned. Let's check.
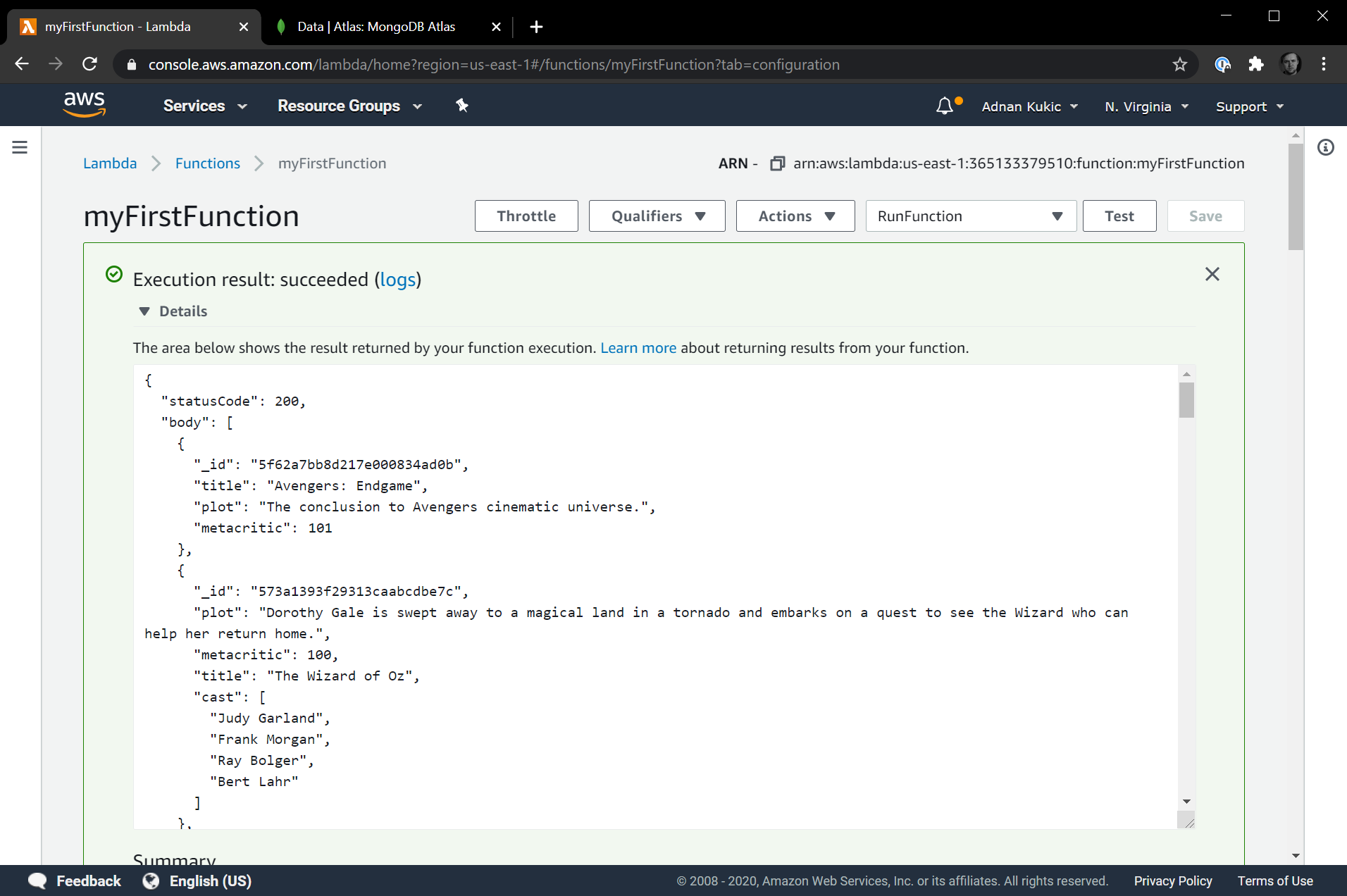
And we're good. Our Avengers movie that we added with our second serverless function is now returned as the first result because it has the highest metacritic rating.
#Putting It All Together
We did it! We created our first, and second AWS Lambda serverless functions. We learned how to expose our AWS Lambda serverless functions to the world using AWS API Gateway, and finally we learned how to integrate MongoDB Atlas in our serverless functions. This is just scratching the surface. I made a few call outs throughout the article saying that the reason we're doing things a certain way is for brevity, but if you are building real world applications I want to leave you with a couple of resources and additional reading.
If you have any questions or feedback, join us on the MongoDB Community forums and let's keep the conversation going!