
No matter what you're building with MongoDB, at some point you'll want to import some data. Whether it's the majority of your data, or just some reference data that you want to integrate with your main data set, you'll find yourself with a bunch of JSON or CSV files that you need to import into a collection. Fortunately, MongoDB provides a tool called mongoimport which is designed for this task. This guide will explain how to effectively use mongoimport to get your data into your MongoDB database.
We also provide MongoImport Reference documentation, if you're looking for something comprehensive or you just need to look up a command-line option.
#Prerequisites
This guide assumes that you're reasonably comfortable with the
command-line. Most of the guide will just be running commands, but
towards the end I'll show how to pipe data through some command-line
tools, such as jq.
If you haven't had much experience on the command-line (also sometimes called the terminal, or shell, or bash), why not follow along with some of the examples? It's a great way to get started.
The examples shown were all written on MacOS, but should run on any unix-type system. If you're running on Windows, I recommend running the example commands inside the Windows Subsystem for Linux.
You'll need a temporary MongoDB database to test out these commands. If you're just getting started, I recommend you sign up for a free MongoDB Atlas account, and then we'll take care of the cluster for you!
And of course, you'll need a copy of mongoimport. If you have
MongoDB installed on your workstation then you may already have
mongoimport installed. If not, follow these
instructions
on the MongoDB website to install it.
I've created a GitHub repo of sample data, containing an extract from the New York Citibike dataset in different formats that should be useful for trying out the commands in this guide.
#Getting Started with mongoimport
mongoimport is a powerful command-line tool for importing data from
JSON, CSV, and TSV files into MongoDB collections. It's super-fast and
multi-threaded, so in many cases will be faster than any custom script
you might write to do the same thing. mongoimport use can be
combined with some other command-line tools, such as jq for JSON
manipulation, or csvkit for CSV manipulation, or even curl for
dynamically downloading data files from servers on the internet. As with
many command-line tools, the options are endless!
#Choosing a Source Data Format
In many ways, having your source data in JSON files is better than CSV
(and TSV). JSON is both a hierarchical data format, like MongoDB
documents, and is also explicit about the types of data it encodes. On
the other hand, source JSON data can be difficult to deal with - in many
cases it is not in the structure you'd like, or it has numeric data
encoded as strings, or perhaps the date formats are not in a form that
mongoimport accepts.
CSV (and TSV) data is tabular, and each row will be imported into
MongoDB as a separate document. This means that these formats cannot
support hierarchical data in the same way as a MongoDB document can.
When importing CSV data into MongoDB, mongoimport will attempt to
make sensible choices when identifying the type of a specific field,
such as int32 or string. This behaviour can be overridden with
the use of some flags, and you can specify types if you want to.
On top of that, mongoimport supplies some facilities for parsing dates and other types in different formats.
In many cases, the choice of source data format won't be up to you - it'll be up to the organisation generating the data and providing it to you. I recommend if the source data is in CSV form then you shouldn't attempt to convert it to JSON first unless you plan to restructure it.
#Connect mongoimport to Your Database
This section assumes that you're connecting to a relatively straightforward setup - with a default authentication database and some authentication set up. (You should always create some users for authentication!)
If you don't provide any connection details to mongoimport, it will
attempt to connect to MongoDB on your local machine, on port 27017
(which is MongoDB's default). This is the same as providing
--host=localhost:27017.
#One URI to Rule Them All
There are several options that allow you to provide separate connection
information to mongoimport, but I recommend you use the --uri option.
If you're using Atlas you can get the appropriate connection
URI from the Atlas interface, by clicking on your cluster's "Connect"
button and selecting "Connect your Application".
(Atlas is being continuously developed, so these instructions may be slightly out of date.)
Set the URI as the value of your --uri option, and replace the username and password with the appropriate values:
1 mongoimport --uri 'mongodb+srv://MYUSERNAME:SECRETPASSWORD@mycluster-ABCDE.azure.mongodb.net/test?retryWrites=true&w=majority'
Be aware that in this form the username and password must be
URL-encoded. If you don't want to worry about this, then provide the
username and password using the --username and --password
options instead:
1 mongoimport --uri 'mongodb+srv://mycluster-ABCDE.azure.mongodb.net/test?retryWrites=true&w=majority' \ 2 --username='MYUSERNAME' \ 3 --password='SECRETPASSWORD'
If you omit a password from the URI and do not provide a --password
option, then mongoimport will prompt you for a password on the
command-line. In all these cases, using single-quotes around values, as
I've done, will save you problems in the long-run!
If you're not connecting to an Atlas database, then you'll have to
generate your own URI. If you're connecting to a single server (i.e. you
don't have a replicaset), then your URI will look like this:
mongodb://your.server.host.name:port/. If you're running a
replicaset (and you should!) then you have more than one hostname to
connect to, and you don't know in advance which is the primary. In this
case, your URI will consist of a series of servers in your cluster (you
don't need to provide all of your cluster's servers, providing one of
them is available), and mongoimport will discover and connect to the
primary automatically. A replicaset URI looks like this:
mongodb://username:password@host1:port,host2:port/?replicaSet=replicasetname.
Full details of the supported URI formats can be found in our reference documentation.
There are also many other options available and these are documented in the mongoimport reference documentation.
Once you've determined the URI, then the fun begins. In the rest of this guide, I'll leave those flags out. You'll need to add them in when trying out the various other options.
#Import One JSON Document
The simplest way to import a single file into MongoDB is to use the
--file option to specify a file. In my opinion, the very best
situation is that you have a directory full of JSON files which need to
be imported. Ideally each JSON file contains one document you wish to
import into MongoDB, it's in the correct structure, and each of the
values is of the correct type. Use this option when you wish to import a
single file as a single document into a MongoDB collection.
You'll find data in this format in the 'file_per_document' directory in the sample data GitHub repo. Each document will look like this:
1 { 2 "tripduration": 602, 3 "starttime": "2019-12-01 00:00:05.5640", 4 "stoptime": "2019-12-01 00:10:07.8180", 5 "start station id": 3382, 6 "start station name": "Carroll St & Smith St", 7 "start station latitude": 40.680611, 8 "start station longitude": -73.99475825, 9 "end station id": 3304, 10 "end station name": "6 Ave & 9 St", 11 "end station latitude": 40.668127, 12 "end station longitude": -73.98377641, 13 "bikeid": 41932, 14 "usertype": "Subscriber", 15 "birth year": 1970, 16 "gender": "male" 17 }
1 mongoimport --collection='mycollectionname' --file='file_per_document/ride_00001.json'
The command above will import all of the json file into a collection
mycollectionname. You don't have to create the collection in
advance.
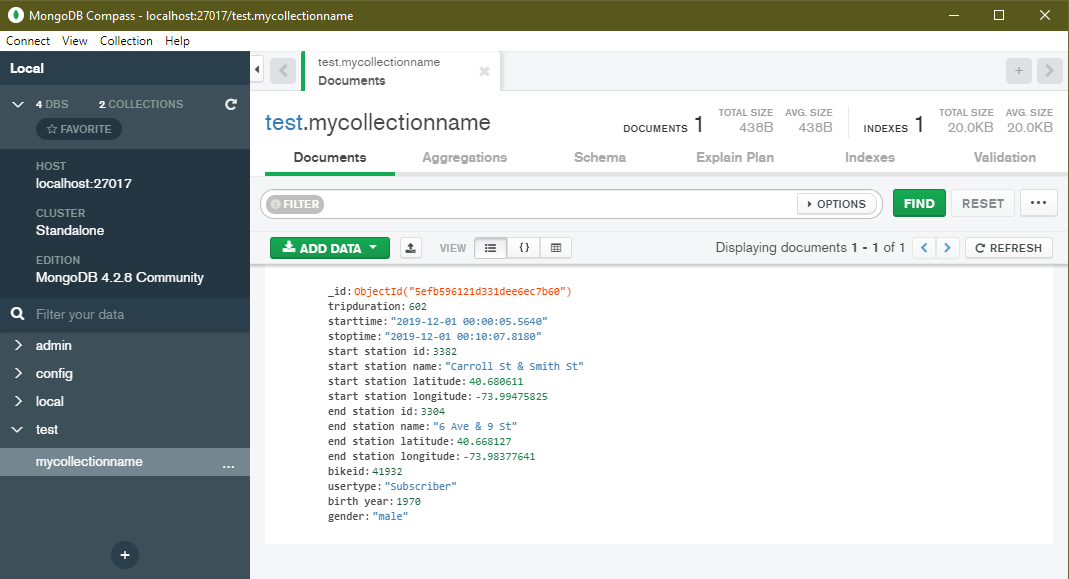
If you use MongoDB Compass or
another tool to connect to the collection you just created, you'll see
that MongoDB also generated an _id value in each document for you.
This is because MongoDB requires every document to have a unique
_id, but you didn't provide one. I'll cover more on this shortly.
#Import Many JSON Documents
Mongoimport will only import one file at a time with the --file
option, but you can get around this by piping multiple JSON documents
into mongoimport from another tool, such as cat. This is faster than
importing one file at a time, running mongoimport from a loop, as
mongoimport itself is multithreaded for faster uploads of multiple
documents. With a directory full of JSON files, where each JSON file
should be imported as a separate MongoDB document can be imported by
cd-ing to the directory that contains the JSON files and running:
1 cat *.json | mongoimport --collection='mycollectionname'
As before,
MongoDB creates a new _id for each document inserted into the MongoDB collection,
because they're not contained in the source data.
#Import One Big JSON Array
Sometimes you will have multiple documents contained in a JSON array in a single document, a little like the following:
1 [ 2 { title: "Document 1", data: "document 1 value"}, 3 { title: "Document 2", data: "document 2 value"} 4 ]
You can import data in this format using the --file option, using
the --jsonArray option:
1 mongoimport --collection='from_array_file' --file='one_big_list.json' --jsonArray
If you forget to add the --jsonArray option,
mongoimport will fail with the error "cannot decode array into a Document."
This is because documents are equivalent to JSON objects, not arrays.
You can store an array as a _value_ on a document,
but a document cannot be an array.
#Import MongoDB-specific Types with JSON
If you import some of the JSON data from the sample data github repo and then view the collection's schema in Compass, you may notice a couple of problems:
- The values of
starttimeandstoptimeshould be "date" types, not "string". - MongoDB supports geographical points, but doesn't recognize the start and stop stations' latitudes and longitudes as such.
This stems from a fundamental difference between MongoDB documents and JSON documents. Although MongoDB documents often look like JSON data, they're not. MongoDB stores data as BSON. BSON has multiple advantages over JSON. It's more compact, it's faster to traverse, and it supports more types than JSON. Among those types are Dates, GeoJSON types, binary data, and decimal numbers. All the types are listed in the MongoDB documentation
If you want MongoDB to recognise fields being imported from JSON as specific BSON types, those fields must be manipulated so that they follow a structure we call Extended JSON. This means that the following field:
1 "starttime": "2019-12-01 00:00:05.5640"
must be provided to MongoDB as:
1 "starttime": { 2 "$date": "2019-12-01T00:00:05.5640Z" 3 }
for it to be recognized as a Date type. Note that the format of the date string has changed slightly, with the 'T' separating the date and time, and the Z at the end, indicating UTC timezone.
Similarly, the latitude and longitude must be converted to a GeoJSON Point type if you wish to take advantage of MongoDB's ability to search location data. The two values:
1 "start station latitude": 40.680611, 2 "start station longitude": -73.99475825,
must be provided to mongoimport in the following GeoJSON Point
form:
1 "start station location": { 2 "type": "Point", 3 "coordinates": [ -73.99475825, 40.680611 ] 4 }
Note: the pair of values are longitude then latitude, as this sometimes catches people out!
Once you have geospatial data in your collection, you can use MongoDB's geospatial queries to search for data by location.
If you need to transform your JSON data in this kind of way, see the section on JQ.
#Importing Data Into Non-Empty Collections
When importing data into a collection which already contains documents,
your _id value is important. If your incoming documents don't
contain _id values, then new values will be created and assigned to
the new documents as they are added to the collection. If your incoming
documents do contain _id values, then they will be checked against
existing documents in the collection. The _id value must be unique
within a collection. By default, if the incoming document has an _id
value that already exists in the collection, then the document will be
rejected and an error will be logged. This mode (the default) is called
"insert mode". There are other modes, however, that behave differently
when a matching document is imported using mongoimport.
#Update Existing Records
If you are periodically supplied with new data files you can use
mongoimport to efficiently update the data in your collection. If
your input data is supplied with a stable identifier, use that field as
the _id field, and supply the option --mode=upsert. This mode
will insert a new document if the _id value is not currently present
in the collection. If the _id value already exists in a document,
then that document will be overwritten by the new document data.
If you're upserting records that don't have stable IDs, you can specify some fields to use to match against documents in the collection, with the --upsertFields option.
If you're using more than one field name, separate these values with a comma:
1 --upsertFields=name,address,height
Remember to index these fields,
if you're using --upsertFields,
otherwise it'll be slow!
#Merge Data into Existing Records
If you are supplied with data files which extend your existing
documents by adding new fields, or update certain fields, you can use
mongoimport with "merge mode". If your input data is supplied with a
stable identifier, use that field as the _id field, and supply the
option --mode=merge. This mode will insert a new document if the
_id value is not currently present in the collection. If the _id
value already exists in a document, then that document will be
overwritten by the new document data.
You can also use the --upsertFields option here as well as when you're doing upserts,
to match the documents you want to update.
#Import CSV (or TSV) into a Collection
If you have CSV files (or TSV files - they're conceptually the same) to
import, use the --type=csv or --type=tsv option to tell
mongoimport what format to expect. Also important is to know whether
your CSV file has a header row - where the first line doesn't contain
data - instead it contains the name for each column. If you do have a
header row, you should use the --headerline option to tell
mongoimport that the first line should not be imported as a
document.
With CSV data, you may have to do some extra work to annotate the data to get it to import correctly. The primary issues are:
- CSV data is "flat" - there is no good way to embed sub-documents in a row of a CSV file, so you may want to restructure the data to match the structure you wish to have in your MongoDB documents.
- CSV data does not include type information.
The first problem is a probably bigger issue. You have two options. One
is to write a script to restructure the data before using
mongoimport to import the data. Another approach could be to import
the data into MongoDB and then run an aggregation pipeline to transform
the data into your required structure.
Both of these approaches are out of the scope of this blog post. If it's something you'd like to see more explanation of, head over to the MongoDB Community Forums.
The fact that CSV files don't specify the type of data in each field can
be solved by specifying the field types when calling mongoimport.
#Specify Field Types
If you don't have a header row, then you must tell mongoimport the
name of each of your columns, so that mongoimport knows what to call
each of the fields in each of the documents to be imported. There are
two methods to do this: You can list the field names on the command-line
with the --fields option, or you can put the field names in a file,
and point to it with the --fieldFile option.
1 mongoimport \ 2 --collection='fields_option' \ 3 --file=without_header_row.csv \ 4 --type=csv \ 5 --fields="tripduration","starttime","stoptime","start station id","start station name","start station latitude","start station longitude","end station id","end station name","end station latitude","end station longitude","bikeid","usertype","birth year","gender"
That's quite a long line! In cases where there are lots of columns it's a good idea to manage the field names in a field file.
#Use a Field File
A field file is a list of column names, with one name per line. So the
equivalent of the --fields value from the call above looks like
this:
1 tripduration 2 starttime 3 stoptime 4 start station id 5 start station name 6 start station latitude 7 start station longitude 8 end station id 9 end station name 10 end station latitude 11 end station longitude 12 bikeid 13 usertype 14 birth year 15 gender
If you put that content in a file called 'field_file.txt' and then run the following command, it will use these column names as field names in MongoDB:
1 mongoimport \ 2 --collection='fieldfile_option' \ 3 --file=without_header_row.csv \ 4 --type=csv \ 5 --fieldFile=field_file.txt

If you open Compass and look at the schema for either 'fields_option' or
'fieldfile_option', you should see that mongoimport has
automatically converted integer types to int32 and kept the latitude
and longitude values as double which is a real type, or
floating-point number.
In some cases, though, MongoDB may make an incorrect decision.
In the screenshot above,
you can see that the 'starttime' and 'stoptime' fields have been imported as strings.
Ideally they would have been imported as a BSON date type,
which is more efficient for storage and filtering.
In this case, you'll want to specify the type of some or all of your columns.
#Specify Types for CSV Columns
All of the types you can specify are listed in our reference documentation
To tell mongoimport you wish to specify the type of some or all of
your fields, you should use the --columnsHaveTypes option. As well
as using the --columnsHaveTypes option, you will need to specify the
types of your fields. If you're using the --fields option, you can
add type information to that value, but I highly recommend adding type
data to the field file. This way it should be more readable and
maintainable, and that's what I'll demonstrate here.
I've created a file called field_file_with_types.txt, and entered
the following:
1 tripduration.auto() 2 starttime.date(2006-01-02 15:04:05) 3 stoptime.date(2006-01-02 15:04:05) 4 start station id.auto() 5 start station name.auto() 6 start station latitude.auto() 7 start station longitude.auto() 8 end station id.auto() 9 end station name.auto() 10 end station latitude.auto() 11 end station longitude.auto() 12 bikeid.auto() 13 usertype.auto() 14 birth year.auto() 15 gender.auto()
Because mongoimport already did the right thing with most of the
fields, I've set them to auto() - the type information comes after a
period (.). The two time fields, starttime and stoptime were
being incorrectly imported as strings, so in these cases I've specified
that they should be treated as a date type. Many of the types take
arguments inside the parentheses. In the case of the date type, it
expects the argument to be a date formatted in the same way you expect
the column's values to be formatted. See the reference
documentation
for more details.
Now, the data can be imported with the following call to
mongoimport:
1 mongoimport --collection='with_types' \ 2 --file=without_header_row.csv \ 3 --type=csv \ 4 --columnsHaveTypes \ 5 --fieldFile=field_file_with_types.txt
#And The Rest
Hopefully you now have a good idea of how to use mongoimport and of
how flexible it is! I haven't covered nearly all of the options that can
be provided to mongoimport, however, just the most important ones.
Others I find useful frequently are:
| Option | Description |
|---|---|
--ignoreBlanks | Ignore fields or columns with empty values. |
--drop | Drop the collection before importing the new documents. This is particularly useful during development, but will lose data if you use it accidentally. |
--stopOnError | Another option that is useful during development, this causes mongoimport to stop immediately when an error occurs. |
There are many more! Check out the mongoimport reference documentation for all the details.
#Useful Command-Line Tools
One of the major benefits of command-line programs is that they are
designed to work with other command-line programs to provide more
power. There are a couple of command-line programs that I particularly
recommend you look at: jq a JSON manipulation tool, and csvkit a
similar tool for working with CSV files.
#JQ
JQ is a processor for JSON data. It incorporates a powerful filtering and scripting language for filtering, manipulating, and even generating JSON data. A full tutorial on how to use JQ is out of scope for this guide, but to give you a brief taster:
If you create a JQ script called fix_dates.jq containing the
following:
1 .starttime |= { "$date": (. | sub(" "; "T") + "Z") } 2 | .stoptime |= { "$date": (. | sub(" "; "T") + "Z") }
You can now pipe the sample JSON data through this script to modify the
starttime and stoptime fields so that they will be imported into
MongoDB as Date types:
1 echo '
{
"tripduration": 602,
"starttime": "2019-12-01 00:00:05.5640",
"stoptime": "2019-12-01 00:10:07.8180"
}' \ 2 | jq -f fix_dates.jq 3 { 4 "tripduration": 602, 5 "starttime": { 6 "$date": "2019-12-01T00:00:05.5640Z" 7 }, 8 "stoptime": { 9 "$date": "2019-12-01T00:10:07.8180Z" 10 } 11 }
This can be used in a multi-stage pipe, where data is piped into
mongoimport via jq.
The jq tool can be a little fiddly to understand at first, but once
you start to understand how the language works, it is very powerful, and
very fast. I've provided a more complex JQ script example in the sample
data GitHub repo, called
json_fixes.jq. Check it out for more ideas, and the full
documentation on the JQ website.
#CSVKit
In the same way that jq is a tool for filtering and manipulating
JSON data, csvkit is a small collection of tools for filtering and
manipulating CSV data. Some of the tools, while useful in their own
right, are unlikely to be useful when combined with mongoimport.
Tools like csvgrep which filters csv file rows based on expressions,
and csvcut which can remove whole columns from CSV input, are useful
tools for slicing and dicing your data before providing it to
mongoimport.
Check out the csvkit docs for more information on how to use this collection of tools.
#Other Tools
Are there other tools you know of which would work well with
mongoimport? Do you have a great example of using awk to handle
tabular data before importing into MongoDB? Let us know on the
community forums!
#Conclusion
It's a common mistake to write custom code to import data into MongoDB.
I hope I've demonstrated how powerful mongoimport is as a tool for
importing data into MongoDB quickly and efficiently. Combined with other simple
command-line tools, it's both a fast and flexible way to import your
data into MongoDB.