
Depending where you are in your development career or the technologies you've already become familiar with, MongoDB can seem quite intimidating. Maybe you're coming from years of experience with relational database management systems (RDBMS), or maybe you're new to the topic of data persistance in general.
The good news is that MongoDB isn't as scary as you might think, and it is definitely a lot easier when paired with the correct tooling.
In this tutorial, we're going to see how to get started with MongoDB Atlas for hosting our database cluster and the MongoDB Query Language (MQL) for interacting with our data. We won't be exploring any particular programming technology, but everything we see can be easily translated over.
#Hosting MongoDB Clusters in the Cloud with MongoDB Atlas
There are a few ways to get started with MongoDB. You could install a single instance or a cluster of instances on your own hardware which you manage yourself in terms of updates, scaling, and security, or you can make use of MongoDB Atlas which is a database as a service (DBaaS) that makes life quite a bit easier, and in many cases cheaper, or even free.
We're going to be working with an M0 sized Atlas cluster, which is part of the free tier that MongoDB offers. There's no expiration to this cluster and there's no credit card required in order to deploy it.
#Deploying a Cluster of MongoDB Instances
Before we can use MongoDB in our applications, we need to deploy a cluster. Create a MongoDB Cloud account and into it.
Choose to Create a New Cluster if not immediately presented with the option, and start selecting the features of your cluster.
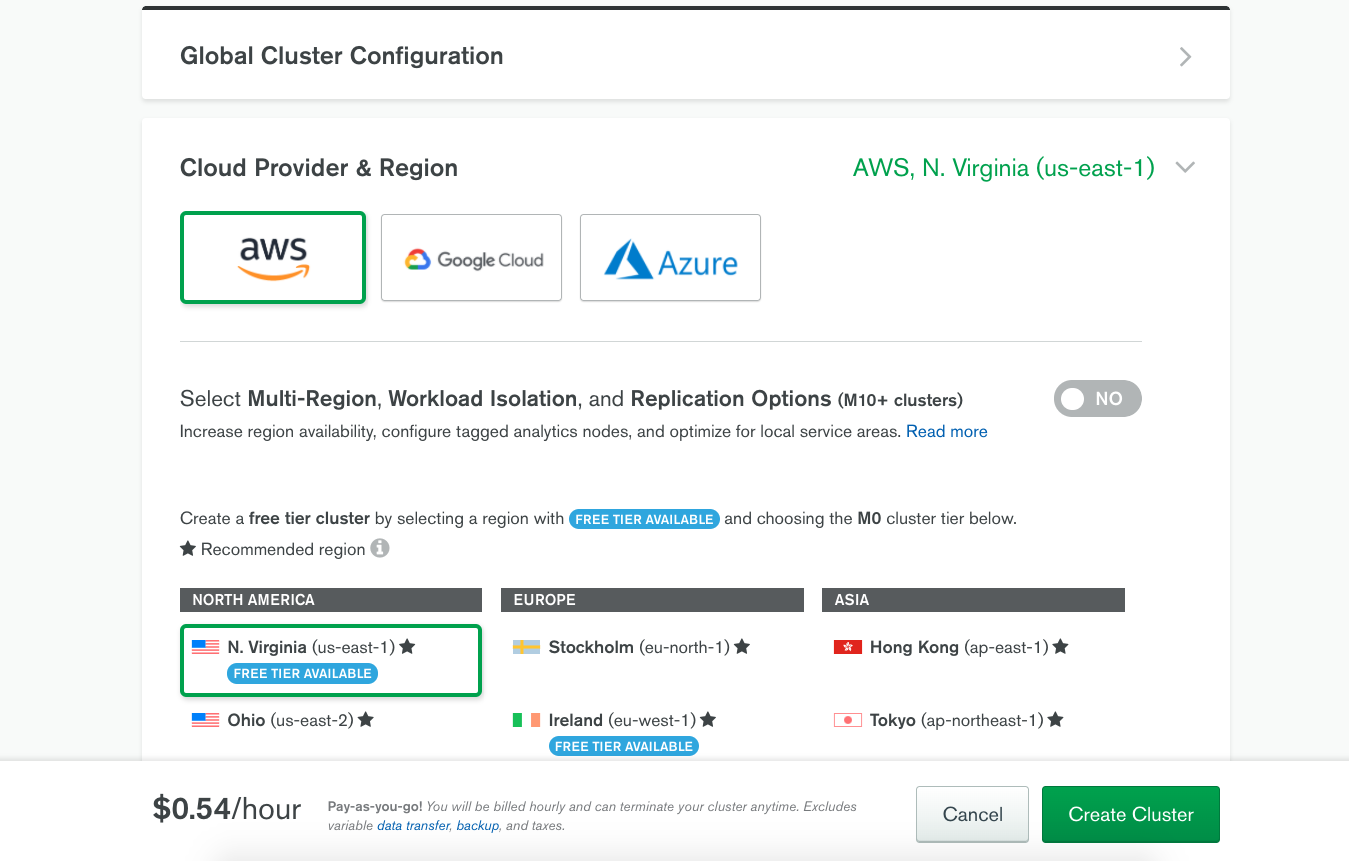
You'll be able to choose between AWS, Google Cloud, and Azure for hosting your cluster. It's important to note that these cloud providers are for location only. You won't ever have to sign into the cloud provider or manage MongoDB through them. The location is important for latency reasons in case you have your applications hosted on a particular cloud provider.
If you want to take advantage of a free cluster, make sure to choose M0 for the cluster size.
It may take a few minutes to finish creating your cluster.
#Defining Network Access Rules for the NoSQL Database Cluster
With the cluster created, you won't be able to access it from outside of the web dashboard by default. This is a good thing because you don't want random people on the internet attempting to gain unauthorized access to your cluster.
To be able to access your cluster from the CLI, a web application, or Visual Studio Code, which we'll be using later, you'll need to setup a network rule that allows access from a particular IP address.
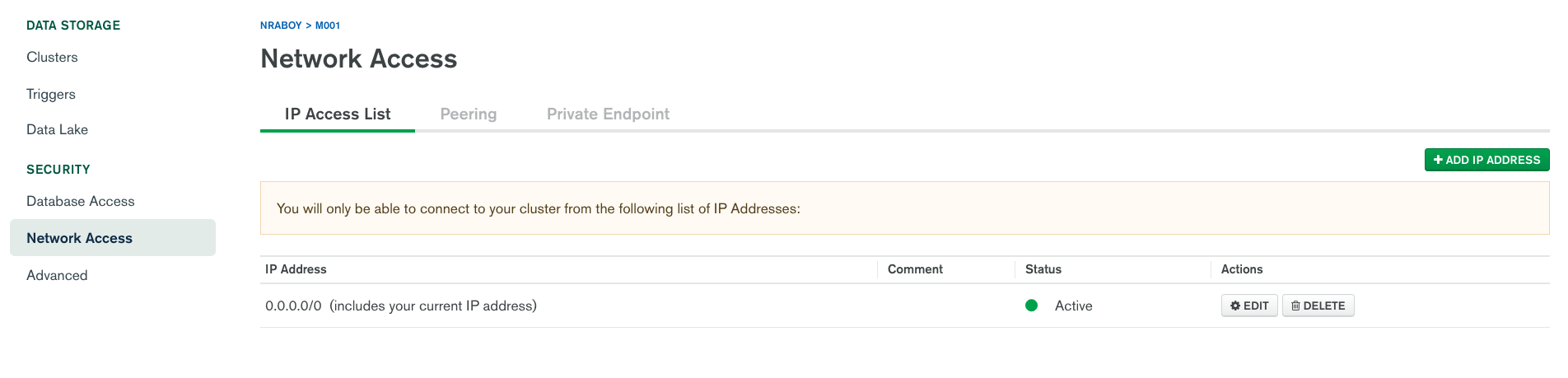
You have a few options when it comes to adding an IP address to the allow list. You could add your current IP address which would be useful for accessing from your local network. You could provide a specific IP address which is useful for applications you host in the cloud somewhere. You can also supply 0.0.0.0/0 which would allow full network access to anyone, anywhere.
I'd strongly recommend not adding 0.0.0.0/0 as a network rule to keep your cluster safe.
With IP addresses on the allow list, the final step is to create an application user.
#Creating Role-Based Access Accounts to Interact with Databases in the Cluster
It is a good idea to create role-based access accounts to your MongoDB Atlas cluster. This means instead of creating one super user like the administrator account, you're creating a user account based on what the user should be doing.
For example, maybe we create a user that has access to your accounting databases and another user that has access to your employee database.
Within Atlas, choose the Database Access tab and click Add New Database User to add a new user.
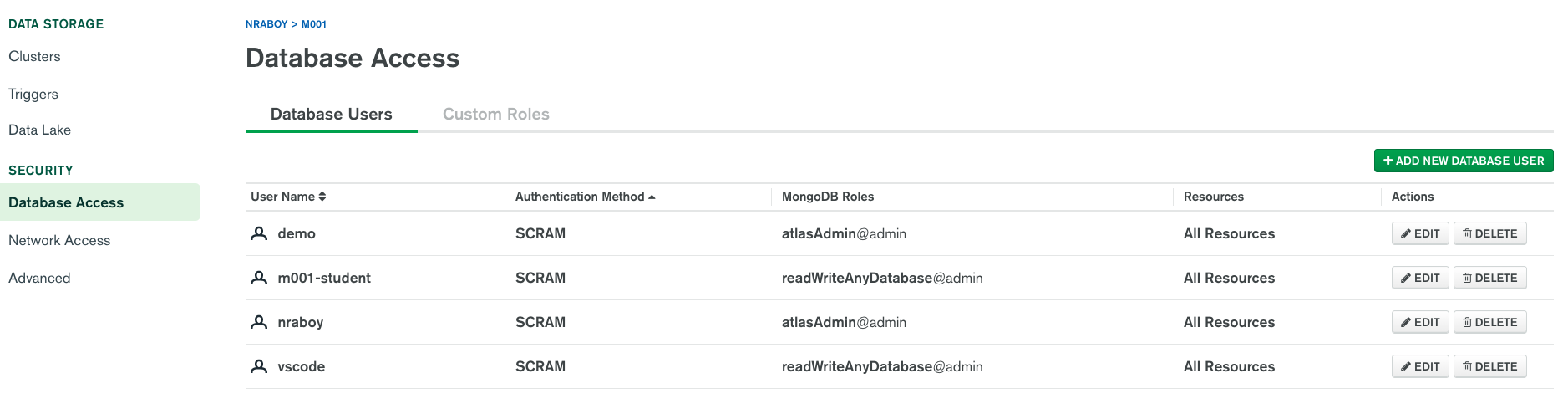
While you can give a user access to every database, current and future, it is best if you create users that have more refined permissions.
It's up to you how you want to create your users, but the more specific the permissions, the less likely your cluster will become compromised by malicious activity.
Need some more guidance around creating an Atlas cluster? Check out this tutorial by Maxime Beugnet on the subject.
With the cluster deployed, the network rules in place for your IP address, and a user created, we can focus on some of the basics behind the MongoDB Query Language (MQL).
#Querying Database Collections with the MongoDB Query Language (MQL)
To get the most out of MongoDB, you're going to need to become familiar with the MongoDB Query Language (MQL). No, it is not like SQL if you're familiar with relational database management systems (RDBMS), but it isn't any more difficult. MQL can be used from the CLI, Visual Studio Code, the development drivers, and more. You'll get the same experience no matter where you're trying to write your queries.
In this section, we're going to focus on Visual Studio Code and the MongoDB Playground extension for managing our data. We're doing this because Visual Studio Code is common developer tooling and it makes for an easy to use experience.
#Configuring Visual Studio Code for the MongoDB Playground
While we could write our queries out of the box with Visual Studio Code, we won't be able to interact with MongoDB in a meaningful way until we install the MongoDB Playground extension.
Within Visual Studio Code, bring up the extensions explorer and search for MongoDB.
Install the official extension with MongoDB as the publisher.
With the extension installed, we'll need to interact with it from within Visual Studio Code. There are a few ways to do this, but we're going to use the command palette.
Open the command pallette (cmd + shift + p, if you're on macOS), and enter MongoDB: Connect into the input box.
You'll be able to enter the information for your particular MongoDB cluster. Once connected, we can proceed to creating a new Playground. If you've already saved your information into the Visual Studio Code extension and need to connect later, you can always enter Show MongoDB in the command pallette and connect.
Assuming we're connected, enter Create MongoDB Playground in the command pallette to create a new file with boilerplate MQL.
#Defining a Data Model and a Use Case for MongoDB
Rather than just creating random queries that may or may not be helpful or any different from what you'd find the documentation, we're going to come up with a data model to work with and then interact with that data model.
I'm passionate about gaming, so our example will be centered around some game data that might look like this:
1 { 2 "_id": "nraboy", 3 "name": "Nic Raboy", 4 "stats": { 5 "wins": 5, 6 "losses": 10, 7 "xp": 300 8 }, 9 "achievements": [ 10 { "name": "Massive XP", "timestamp": 1598961600000 }, 11 { "name": "Instant Loss", "timestamp": 1598896800000 } 12 ] 13 }
The above document is just one of an endless possibility of data models for a document in any given collection. To make the example more exciting, the above document has a nested object and a nested array of objects, something that demonstrates the power of JSON, but without sacrificing how easy it is to work with in MongoDB.
The document above is often referred to as a user profile document in game development. You can learn more about user profile stores in game development through a previous Twitch stream on the subject.
As of right now, it's alright if your cluster has no databases, collections, or even documents that look like the above document. We're going to get to that next.
#Create, Read, Update, and Delete (CRUD) Documents in a Collections
When working with MongoDB, you're going to get quite familiar with the create, read, update, and delete (CRUD) operations necessary when working with data. To reiterate, we'll be using Visual Studio Code to do all this, but any CRUD operation you do in Visual Studio Code, can be taken into your application code, scripts, and similar.
Earlier you were supposed to create a new MongoDB Playground in Visual Studio Code. Open it, remove all the boilerplate MQL, and add the following:
1 use("gamedev"); 2 3 db.profiles.insertOne({ 4 "_id": "nraboy", 5 "name": "Nic Raboy", 6 "stats": { 7 "wins": 5, 8 "losses": 10, 9 "xp": 300 10 }, 11 "achievements": [ 12 { "name": "Massive XP", "timestamp": 1598961600000 }, 13 { "name": "Instant Loss", "timestamp": 1598896800000 } 14 ] 15 });
In the above code we are declaring that we want to use a gamedev database in our queries that follow. It's alright if such a database doesn't already exist because it will be created at runtime.
Next we're using the insertOne operation in MongoDB to create a
single document. The db object references the gamedev database
that we've chosen to use. The profiles object references a
collection that we want to insert our document into.
The profiles collection does not need to exist prior to inserting our first document.
It does not matter what we choose to call our database as well as our collection. As long as the name makes sense to you and the use-case that you're trying to fulfill.
Within Visual Studio Code, you can highlight the above MQL and choose Run Selected Lines From Playground or use the command pallette to run the entire playground. After running the MQL, check out your MongoDB Atlas cluster and you should see the database, collection, and document created.
More information on the insert function can be found in the
official
documentation.
If you'd rather verify the document was created without actually navigating through MongoDB Atlas, we can move onto the next stage of the CRUD operation journey.
Within the playground, add the following:
1 use("gamedev"); 2 3 db.profiles.find({});
The above find operation will return all documents in the
profiles collection. If you wanted to narrow the result-set, you
could provide filter criteria instead of providing an empty object. For
example, try executing the following instead:
1 use("gamedev"); 2 3 db.profiles.find({ "name": "Nic Raboy" });
The above find operation will only return documents where the
name field matches exactly Nic Raboy. We can do better though.
What about finding documents that sit within a certain range for certain
fields.
Take the following for example:
1 use("gamedev"); 2 3 db.profiles.find( 4 { 5 "stats.wins": { 6 "$gt": 6 7 }, 8 "stats.losses": { 9 "$lt": 11 10 } 11 } 12 );
The above find operation says that we only want documents that have
more than six wins and less than eleven losses. If we were running the
above query with the current dataset shown earlier, no results would be
returned because nothing satisfies the conditions.
You can learn more about the filter operators that can be used in the official documentation.
So we've got at least one document in our collection and have seen the
insertOne and find operators. Now we need to take a look at the
update and delete parts of CRUD.
Let's say that we finished a game and the stats.wins field needs to
be updated. We could do something like this:
1 use("gamedev") 2 3 db.profiles.update( 4 { "_id": "nraboy" }, 5 { "$inc": { "stats.wins": 1 } } 6 );
The first object in the above update operation is the filter. This
is the same filter that can be used in a find operation. Once we've
filtered for documents to update, the second object is the mutation. In
the above example, we're using the $inc operator to increase the
stats.wins field by a value of one.
There are quite a few operators that can be used when updating documents. You can find more information in the official documentation.
Maybe we don't want to use an operator when updating the document. Maybe we want to change a field or add a field that might not exist. We can do something like the following:
1 use("gamedev") 2 3 db.profiles.update( 4 { "_id": "nraboy" }, 5 { "name": "Nicolas Raboy" } 6 );
The above query will filter for documents with an _id of nraboy, and then update the name
field on those documents to be a particular string, in this case "Nicolas Raboy". If the name
field doesn't exist, it will be created and set.
Got a document you want to remove? Let's look at the final part of the CRUD operators.
Add the following to your playground:
1 use("gamedev") 2 3 db.profiles.remove({ "_id": "nraboy" })
The above remove operation uses a filter, just like what we saw with
the find and update operations. We provide it a filter of
documents to find and in this circumstance, any matches will be removed
from the profiles collection.
To learn more about the remove function, check out the official
documentation.
#Complex Queries with the MongoDB Data Aggregation Pipeline
For a lot of applications, you might only need to ever use basic CRUD operations when working with MongoDB. However, when you need to start analyzing your data or manipulating your data for the sake of reporting, running a bunch of CRUD operations might not be your best bet.
This is where a MongoDB data aggregation pipeline might come into use.
To get an idea of what a data aggregation pipeline is, think of it as a series of data stages that must complete before you have your data.
Let's use a better example. Let's say that you want to look at your profiles collection and determine all the players who received a certain achievement after a certain date. However, you only want to know the specific achievement and basic information about the player. You don't want to know generic information that matched your query.
Take a look at the following:
1 use("gamedev") 2 3 db.profiles.aggregate([ 4 { "$match": { "_id": "nraboy" } }, 5 { "$unwind": "$achievements" }, 6 { 7 "$match": { 8 "achievements.timestamp": { 9 "$gt": new Date().getTime() - (1000 * 60 * 60 * 24 * 1) 10 } 11 } 12 }, 13 { "$project": { "_id": 1, "achievements": 1 }} 14 ]);
There are four stages in the above pipeline. First we're doing a
$match to find all documents that match our filter. Those documents
are pushed to the next stage of the pipeline. Rather than looking at and
trying to work with the achievements field which is an array, we are
choosing to $unwind it.
To get a better idea of what this looks like, at the end of the second stage, any data that was found would look like this:
1 [ 2 { 3 "_id": "nraboy", 4 "name": "Nic Raboy", 5 "stats": { 6 "wins": 5, 7 "losses": 10, 8 "xp": 300 9 }, 10 "achievements": { 11 "name": "Massive XP", 12 "timestamp": 1598961600000 13 } 14 }, 15 { 16 "_id": "nraboy", 17 "name": "Nic Raboy", 18 "stats": { 19 "wins": 5, 20 "losses": 10, 21 "xp": 300 22 }, 23 "achievements": { 24 "name": "Instant Loss", 25 "timestamp": 1598896800000 26 } 27 } 28 ]
Notice in the above JSON response that we are no longer working with an
array. We should have only matched on a single document, but the results
are actually two instead of one. That is because the $unwind split
the array into numerous objects.
So we've flattened the array, now we're onto the third stage of the pipeline. We want to match any object in the result that has an achievement timestamp greater than a specific time. The plan here is to reduce the result-set of our flattened documents.
The final stage of our pipeline is to output only the fields that we're
interested in. With the $project we are saying we only want the
_id field and the achievements field.
Our final output for this aggregation might look like this:
1 [ 2 { 3 "_id": "nraboy", 4 "achievements": { 5 "name": "Instant Loss", 6 "timestamp": 1598896800000 7 } 8 } 9 ]
There are quite a few operators when it comes to the data aggregation pipeline, many of which can do far more extravagant things than the four pipeline stages that were used for this example. You can learn about the other operators in the official documentation.
#Conclusion
You just got a taste of what you can do with MongoDB Atlas and the MongoDB Query Language (MQL). While the point of this tutorial was to get you comfortable with deploying a cluster and interacting with your data, you can extend your knowledge and this example by exploring the programming drivers.
Take the following quick starts for example:
In addition to the quick starts, you can also check out the MongoDB University course, M121, which focuses on data aggregation.
As previously mentioned, you can take the same queries between languages with minimal to no changes between them.