
Did you know that MongoDB Atlas provides a complete set of example data to help you learn faster? The Load Sample Data feature enables you to load eight datasets into your database to explore. You can use this with the MongoDB Atlas M0 "free tier" to try out MongoDB Atlas and MongoDB's features. The sample data helps you try out features such as indexing, querying including geospatial, and aggregations, as well as using MongoDB Tooling such as MongoDB Charts and MongoDB Compass.
In the rest of this post, we'll explore why it was created, how to first load the sample data, and then we'll outline what the datasets contain. We'll also cover how you can download these datasets to use them on your own local machine.
#Table of Contents
#Why Did We Create This Sample Data Set ?
Before diving into how we load the sample data, it's worth highlighting why we built the feature in the first place. We built this feature because often people would create a new empty Atlas cluster and they'd then have to wait until they wrote their application or imported data into it before they were able to learn and explore the platform. Atlas's Sample Data was the solution. It removes this roadblock and quickly allows you to get a feel for how MongoDB works with different types of data.
#Loading The Sample Data Set Into Your Atlas Cluster
Loading the Sample Data requires an existing Atlas cluster and three steps.
- In your left navigation pane in Atlas, click Clusters, then choose which cluster you want to load the data into.
- For that cluster, click the Ellipsis (...) button.
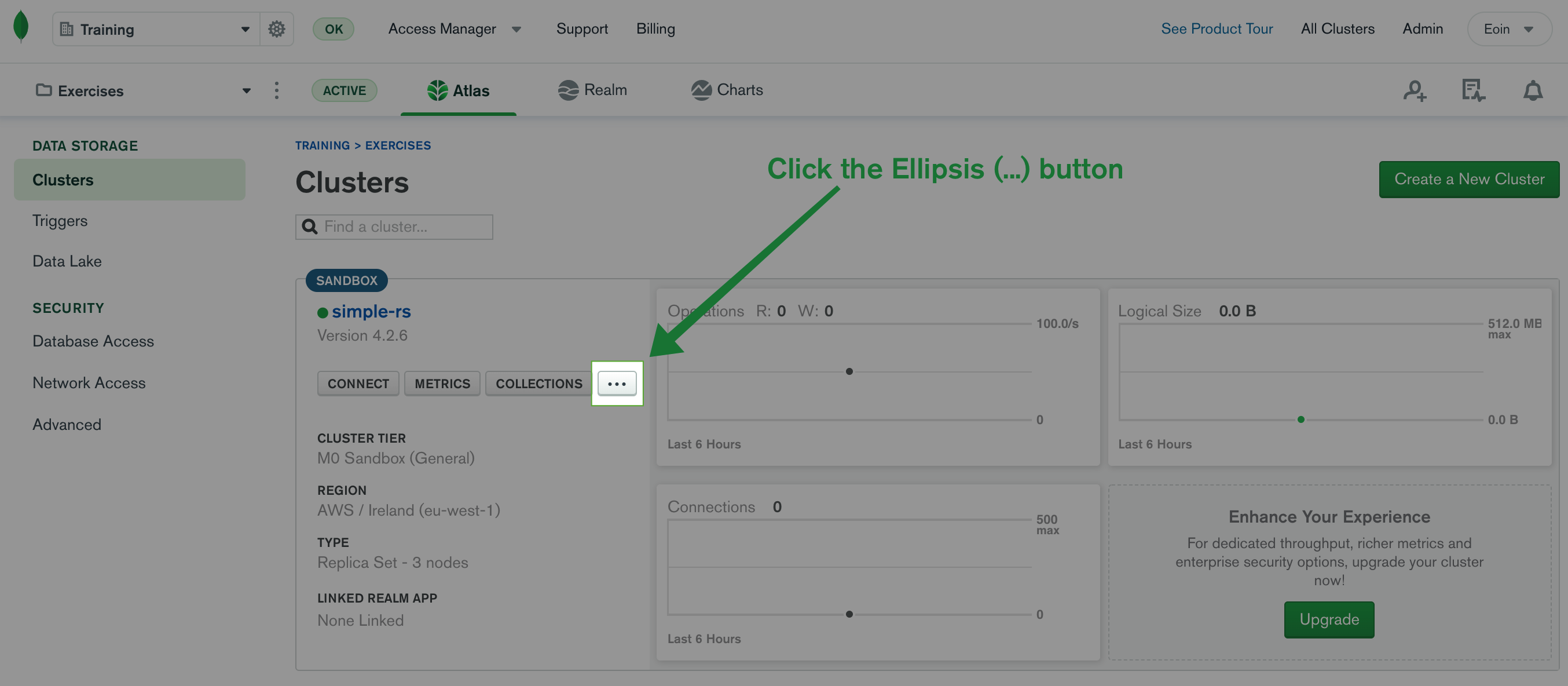
- Then, click the button "Load Sample Dataset".
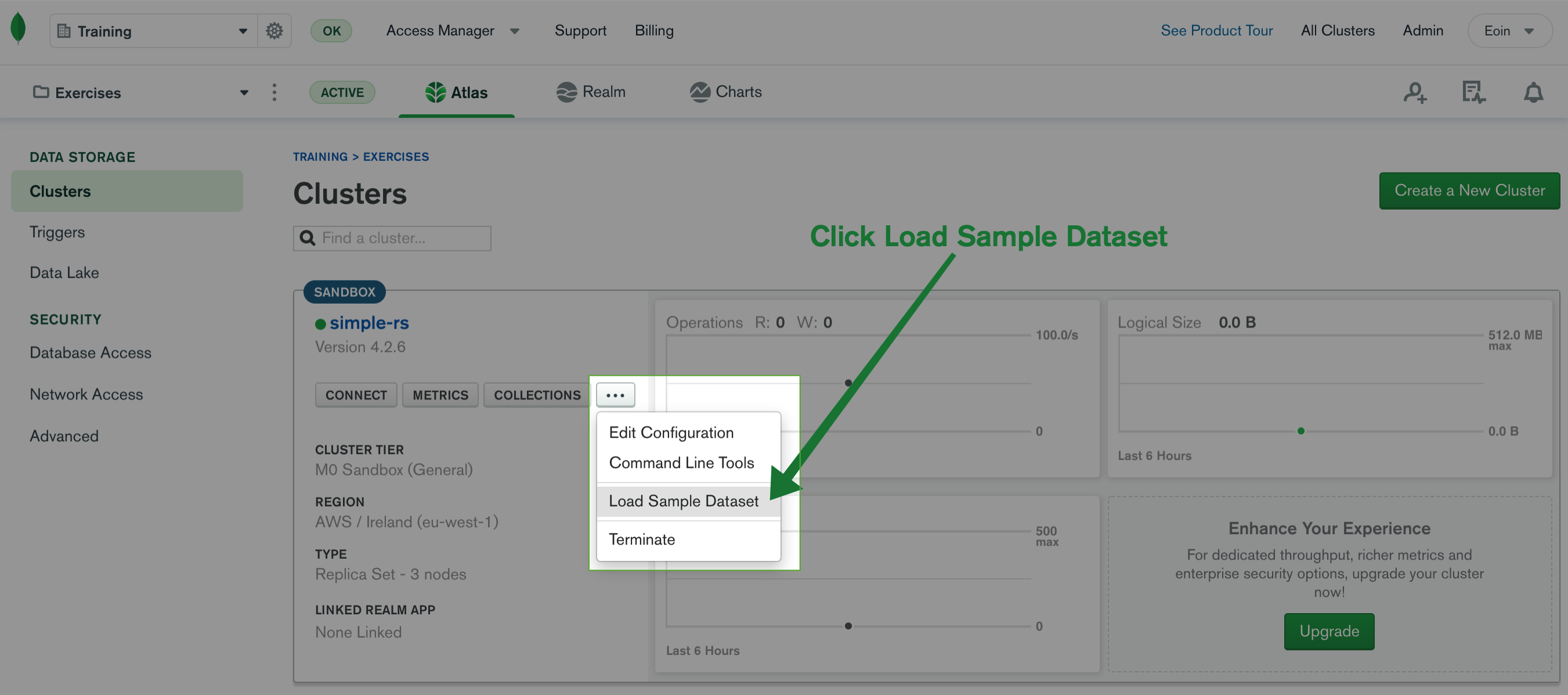
- Click the correspondingly named button, "Load Sample Dataset."
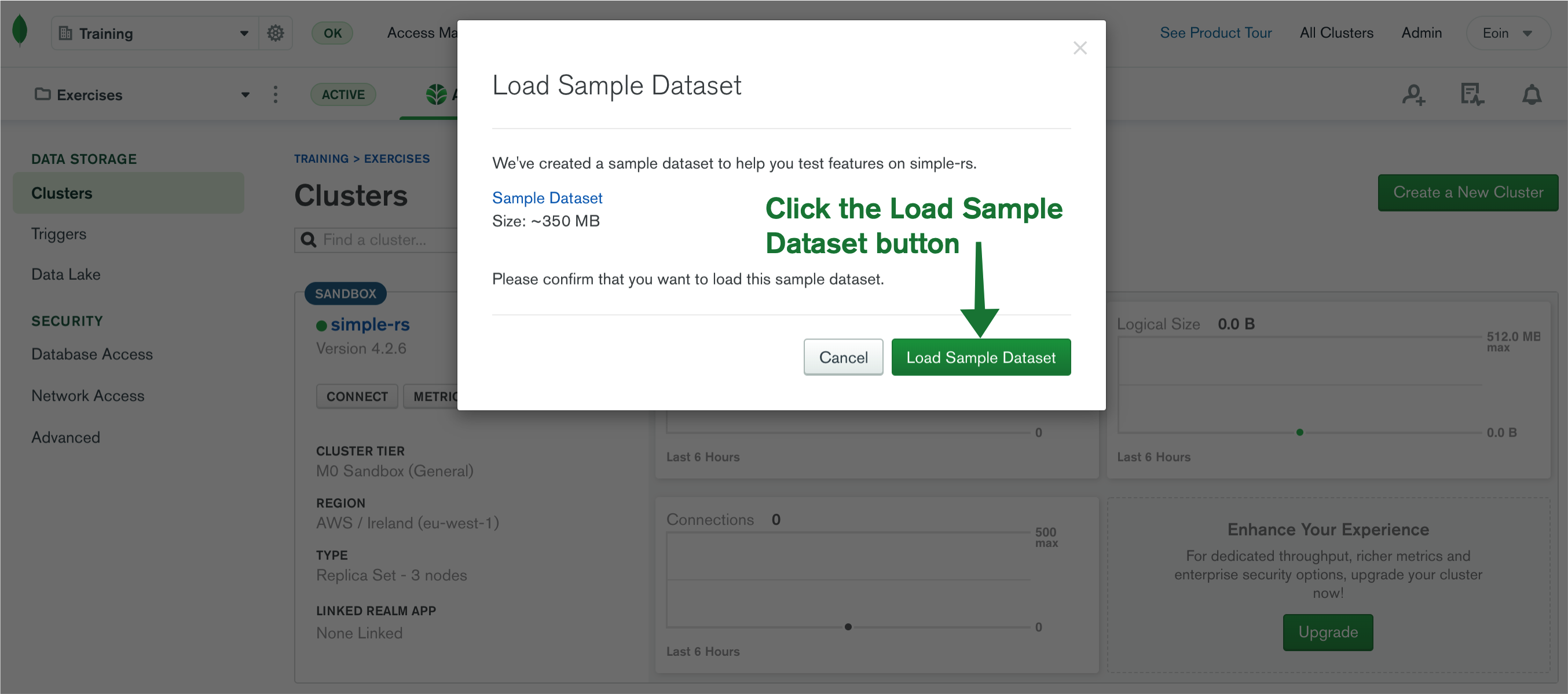
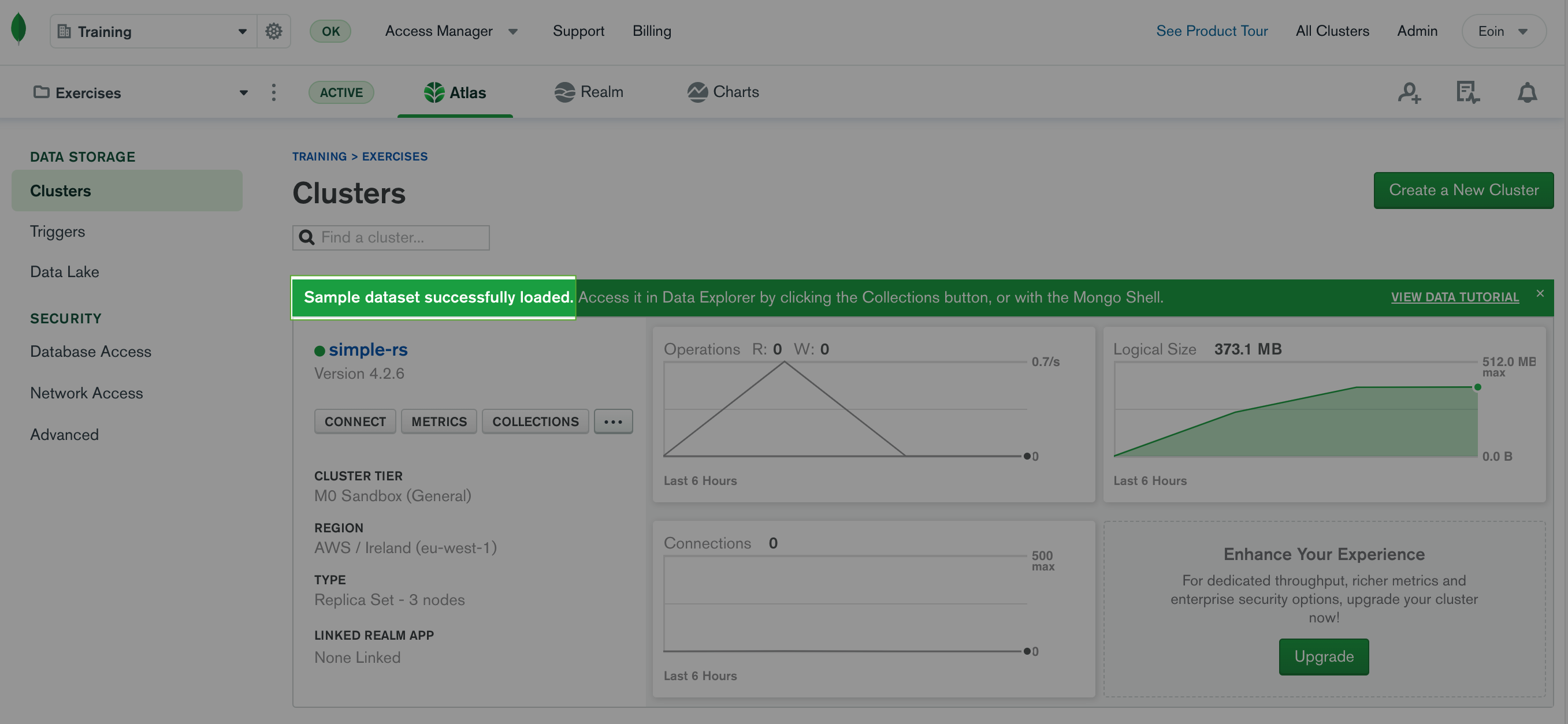
This process will take a few minutes to complete, so let's look at exactly what kind of data we're going to load. Once the process is completed, you should see a banner on your Atlas Cluster similar to this image below.
#A deeper dive into the Atlas Sample Data
The Atlas Sample Datasets are comprised of eight databases and their associated collections. Each individual dataset is documented to illustrate the schema, the collections, the indexes, and a sample document from each collection.
#Sample AirBnB Listings Dataset
This dataset consists of a single collection of AirBnB reviews and listings.
There are indexes on the property type, room type, bed,
name, and on the location fields as well as on the _id of the
documents.
The data is a randomized subset of the original publicly available AirBnB dataset. It covers several different cities around the world. This dataset is used extensively in MongoDB University courses.
You can find more details on the Sample AirBnB Documentation page.
#Sample Analytics Dataset
This dataset consists of three collections of randomly generated financial
services data. There are no additional indexes beyond the _id index on
each collection. The collections represent accounts, transactions, and
customers.
The transactions collection uses the Bucket Pattern to hold a set of transactions for a period. It was built for MongoDB's private training, specifically for the MongoDB for Data Analysis course.
The advantages in using this pattern are a reduction in index size when compared to storing each transaction in a single document. It can potentially simplify queries and it provides the ability to use pre-aggregated data in our documents.
1 // transaction collection document example 2 { 3 "account_id": 794875, 4 "transaction_count": 6, 5 "bucket_start_date": {"$date": 693792000000}, 6 "bucket_end_date": {"$date": 1473120000000}, 7 "transactions": [ 8 { 9 "date": {"$date": 1325030400000}, 10 "amount": 1197, 11 "transaction_code": "buy", 12 "symbol": "nvda", 13 "price": "12.7330024299341033611199236474931240081787109375", 14 "total": "15241.40390863112172326054861" 15 }, 16 { 17 "date": {"$date": 1465776000000}, 18 "amount": 8797, 19 "transaction_code": "buy", 20 "symbol": "nvda", 21 "price": "46.53873172406391489630550495348870754241943359375", 22 "total": "409401.2229765902593427995271" 23 }, 24 { 25 "date": {"$date": 1472601600000}, 26 "amount": 6146, 27 "transaction_code": "sell", 28 "symbol": "ebay", 29 "price": "32.11600884852845894101847079582512378692626953125", 30 "total": "197384.9903830559086514995215" 31 }, 32 { 33 "date": {"$date": 1101081600000}, 34 "amount": 253, 35 "transaction_code": "buy", 36 "symbol": "amzn", 37 "price": "37.77441226157566944721111212857067584991455078125", 38 "total": "9556.926302178644370144411369" 39 }, 40 { 41 "date": {"$date": 1022112000000}, 42 "amount": 4521, 43 "transaction_code": "buy", 44 "symbol": "nvda", 45 "price": "10.763069758141103449133879621513187885284423828125", 46 "total": "48659.83837655592869353426977" 47 }, 48 { 49 "date": {"$date": 936144000000}, 50 "amount": 955, 51 "transaction_code": "buy", 52 "symbol": "csco", 53 "price": "27.992136535152877030441231909207999706268310546875", 54 "total": "26732.49039107099756407137647" 55 } 56 ] 57 }
You can find more details on the Sample Analytics Documentation page.
#Sample Geospatial Dataset
This dataset consists of a single collection with information on shipwrecks.
It has an additional index on the coordinates field (GeoJSON). This
index is a Geospatial 2dsphere index. This dataset was created to help
explore the possibility of geospatial queries within MongoDB.
The image below was created in MongoDB Charts and shows all of the shipwrecks on the eastern seaboard of North America.
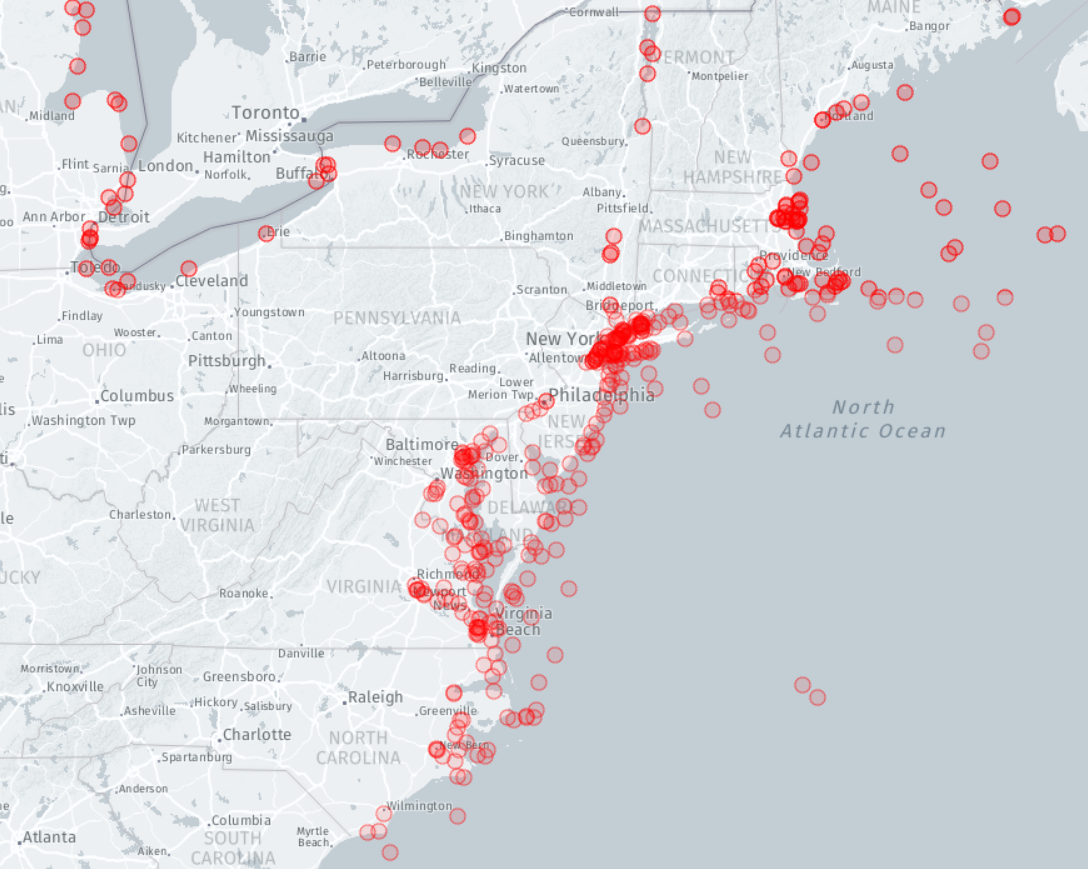
You can find more details on the Sample Geospatial Documentation page.
#Sample Mflix Dataset
This dataset consists of five collections with information on movies,
movie theatres, movie metadata, and user movie reviews and their ratings
for specific movies. The data is a subset of the IMDB dataset. There are
three additional indexes beyond _id: on the sessions collection on the
user_id field, on the theatres collection on the location.geo field,
and on the users collection on the email field. You can see this dataset
used in this MongoDB Charts tutorial.
The Atlas Search Movies site uses this data and MongoDB's Atlas Search to provide a searchable movie catalog.
This dataset is the basis of our Atlas Search tutorial.
You can find more details on the Sample Mflix Documentation page.
#Sample Restaurants Dataset
This dataset consists of two collections with information on restaurants and neighbourhoods in New York. There are no additional indexes. This dataset is the basis of our Geospatial tutorial. The restaurant document only contains the location and the name for a given restaurant.
1 // restaurants collection document example 2 { 3 location: { 4 type: "Point", 5 coordinates: [-73.856077, 40.848447] 6 }, 7 name: "Morris Park Bake Shop" 8 }
In order to use the collections for geographical searching, we need to add an index, specifically a 2dsphere index. We can add this index and then search for all restaurants in a one-kilometer radius of a given location, with the results being sorted by those closest to those furthest away. The code below creates the index, then adds a helper variable to represent 1km, which our query then uses with the $nearSphere criteria to return the list of restaurants within 1km of that location.
1 db.restaurants.createIndex({ location: "2dsphere" }) 2 var ONE_KILOMETER = 1000 3 db.restaurants.find({ location: { $nearSphere: { $geometry: { type: "Point", coordinates: [ -73.93414657, 40.82302903 ] }, $maxDistance: ONE_KILOMETER } } })
You can find more details on the Sample Restaurants Documentation page.
#Sample Supply Store Dataset
This dataset consists of a single collection with information on mock sales data for a hypothetical office supplies company. There are no additional indexes. This is the second dataset used in the MongoDB Chart tutorials.
The sales collection uses the Extended Reference pattern to hold both the items sold and their details as well as information on the customer who purchased these items. This pattern includes frequently accessed fields in the main document to improve performance at the cost of additional data duplication.
1 // sales collection document example 2 { 3 "_id": { 4 "$oid": "5bd761dcae323e45a93ccfe8" 5 }, 6 "saleDate": { 7 "$date": { "$numberLong": "1427144809506" } 8 }, 9 "items": [ 10 { 11 "name": "notepad", 12 "tags": [ "office", "writing", "school" ], 13 "price": { "$numberDecimal": "35.29" }, 14 "quantity": { "$numberInt": "2" } 15 }, 16 { 17 "name": "pens", 18 "tags": [ "writing", "office", "school", "stationary" ], 19 "price": { "$numberDecimal": "56.12" }, 20 "quantity": { "$numberInt": "5" } 21 }, 22 { 23 "name": "envelopes", 24 "tags": [ "stationary", "office", "general" ], 25 "price": { "$numberDecimal": "19.95" }, 26 "quantity": { "$numberInt": "8" } 27 }, 28 { 29 "name": "binder", 30 "tags": [ "school", "general", "organization" ], 31 "price": { "$numberDecimal": "14.16" }, 32 "quantity": { "$numberInt": "3" } 33 } 34 ], 35 "storeLocation": "Denver", 36 "customer": { 37 "gender": "M", 38 "age": { "$numberInt": "42" }, 39 "email": "cauho@witwuta.sv", 40 "satisfaction": { "$numberInt": "4" } 41 }, 42 "couponUsed": true, 43 "purchaseMethod": "Online" 44 }
You can find more details on the Sample Supply Store Documentation page.
#Sample Training Dataset
This dataset consists of nine collections with no additional indexes. It represents a selection of realistic data and is used in the MongoDB private training courses.
It includes a number of public, well-known data sources such as the OpenFlights, NYC's OpenData, and NYC's Citibike Data.
The routes collection uses the Extended Reference pattern
to hold OpenFlights data on airline
routes between airports. It references airline information in the airline
sub document, which has details about the specific plane on the route. This
is another example of improving performance at the cost of minor data
duplication for fields that are likely to be frequently accessed.
1 // routes collection document example 2 { 3 "_id": { 4 "$oid": "56e9b39b732b6122f877fa5c" 5 }, 6 "airline": { 7 "alias": "2G", 8 "iata": "CRG", 9 "id": 1654, 10 "name": "Cargoitalia" 11 }, 12 "airplane": "A81", 13 "codeshare": "", 14 "dst_airport": "OVB", 15 "src_airport": "BTK", 16 "stops": 0 17 }
You can find more details on the Sample Training Documentation page.
#Sample Weather Dataset
This dataset consists of a single collection with no additional indexes. It represents detailed weather reports from locations across the world. It holds geospatial data on the locations in the form of legacy coordinate pairs.
You can find more details on the Sample Weather Documentation page.
If you have ideas or suggestions for new datasets, we are always interested. Let us know on the developer community website.
#Downloading the Dataset for Use on Your Local Machine
It is also possible to download and explore these datasets on your own local machine. You can download the complete sample dataset via the wget command:
1 wget https://atlas-education.s3.amazonaws.com/sampledata.archive
Note: You can also use the curl command:
1 curl https://atlas-education.s3.amazonaws.com/sampledata.archive -o sampledata.archive
You should check you are running a local mongod instance or you should
start a new mongod instance at this point. This mongod will be used
in conjunction with mongorestore to unpack and host a local copy of the
sample dataset. You can find more details on starting mongod instances on
this documentation page.
This section assumes that you're connecting to a relatively straightforward setup, with a default authentication database and some authentication set up. (You should always create some users for authentication!)
If you don't provide any connection details to mongorestore, it will
attempt to connect to MongoDB on your local machine, on port 27017
(which is MongoDB's default). This is the same as providing
--host localhost:27017.
1 mongorestore --archive=sampledata.archive
You can use a variety of tools to view your documents. You can use MongoDB Compass, the CLI, or the MongoDB Visual Studio Code (VSCode) plugin to interact with the documents in your collections. You can find out how to use MongoDB Playground for VSCode and integrate MongoDB into a Visual Studio Code environment.
If you find the sample data useful for building or helpful, let us know on the community forums!
#Wrap Up
These datasets offer a wide selection of data that you can use to both explore MongoDB's features and prototype your next project without having to worry about where you'll find the data.
Check out the documentation on Load Sample Data to learn more on these datasets and load it into your Atlas Cluster today to start exploring it!
To learn more about schema patterns and MongoDB, please check out our blog series Building with Patterns and the free MongoDB University Course M320: Data Modeling to level up your schema design skills.
If you have questions, please head to our developer community website where the MongoDB engineers and the MongoDB community will help you build your next big idea with MongoDB.